
第一部分 Python 入门 #
前言:本系列文章为作者个人学习 Python 数据处理的学习笔记,其中对于书上的一些案例进行了本地实现,以及在实现过程中对出现的一些问题进行了解决和知识拓展,希望可以为阅读笔记的朋友们提供一些帮助。
第一章 为什么要用 Python 为 Excel 编程 #
1.1 Excel 作为一门编程语言 #
1.1.2 编程最佳实践 #
最重要的编程最佳实践,涉及关注点分离、DRY 原则、测试和版本控制。
1. 关注点分离 #
编程最重要的设计原则之一就是关注点分离(separation of concerns),有时候也称作模块化(modularity)。一系列相关的功能应当被视作程序中一个独立的部分来处 理,从而可以在不影响应用程序其他部分的情况下,轻松地替换这一部分.
一个应用程序通常被分为如下 3 层:
• 表示层(presentation layer):这一层是你可以看到并与之交互的部分,也就是所谓的用户界面。
• 业务层(business layer):这一层负责特定应用程序的逻辑。
• 数据层(data layer):这一层负责访问数据。
2. DRY 原则 #
意思是“不要自我重复”(don’t repeat yourself),没有重复的代码意味着代码行数更少,错误也更少,代码自然也就更容易维护。
3. 测试 #
专业软件开发人员测试代码,会写单元测试(unit test)。 这是一种可以测试程序各个组件的机制。单元测试会确保程序中的每一个函数都正常工作。大部分编程语言会提供一种自动执行单元测试的方法。执行自动测试可以使代码库的可靠性大幅提升,并且在一定程度上,测试会确保在编辑代码时不会破坏当前正常工作的代码。
通常程序员会对单元测试进行配置,每当代码被提交到版本控制系统的时候,它就会自动运行。
4. 版本控制 #
专业程序员会使用版本控制(version control)系统,或者称为源代码控制(source control)系统。版本控制系统(version control system,VCS)会不断跟踪源代码的更改,让你能够看到是谁进行了更改,更改了什么,什么时候更改的,为什么更改, 并且在任何时候都能还原到过去的版本。当今最受欢迎的版本控制系统是 Git。
通常专业程序员都会结合像GitHub、GitLab、Bitbucket 和 Azure DevOps 这样的 Web 平台来使用 Git,这些平台可以让你提出所谓的拉取请求 (pull request)和合并请求(merge request)。这些操作可以让开发者正式地请求负责人将他 们的更改合并到主数据库中。一次拉取请求会提供如下信息:
• 更改的作者; • 更改发生的时间; • 在提交信息(commit message)中描述的更改目的; • 在 diff 视图(其中新代码以绿色高亮显示,删掉的代码以红色高亮显示)中展示的更改细节。
1.1.3 现代 Excel #
1. Power Query 和 Power Pivot #
Power Query 可以连接各种数据源,包括 Excel 工作簿、CSV 文件、SQL 数据库,等等。核心功能是处理一张工作表装不下的数据集。在加载数据之后,你还可以通过额外的操作来清理、操作数据,使之成为 Excel 可用的形式。
Power Pivot 和 Power Query 联系密切,利用 Power Query 获取和清理数据之后,就该 Power Pivot 上场了。Power Pivot 以一种引人入胜的方式直接在 Excel 中分析和呈现数据。可以把它视作一种传统意义上的数据透视表。和 Power Query 一样, 它也可以处理大型数据集。Power Pivot 可以用关系和层次来定义形式上的数据模型, 并且可以通过 DAX 公式语言添加计算列。
2. Power BI #
Power BI 是在 2015 年发布的一个独立应用程序。Power BI 通过在交互式仪表板中可视化巨大的数据集使其更容易理解。Power BI 的商业版可以让你在线和他人合作,并共享仪表板。Power BI 自 2018 年起就支持 Python 脚本了。
1.2 用在 Excel 上的 Python #
Excel 的主要功能是存储数据、分析数据和可视化数据。而 Python 在科学计算方面也极其
强大,天生就适合搭配 Excel 工作。
1.2.1 可读性和可维护性 #
良好的可读性使得发现错误和维护代码更加容易,Python 会强制将视觉缩进和代码逻辑对齐,从而避免可读性问题。当你在 if 语句或 for 循环中使用代码块时,Python 依靠缩进来定义代码块。
使用缩进定义代码块的原因在于,编程时大部分时间是花费在维护代码而不是现写新的代码上。可读性好的代码可以帮助新进程序员回顾过去、了解现状。
1.2.2 标准库和包管理器 #
Python 通过标准库提供了丰富的内置工具。Python 社群喜欢称之为“自带电池”。尽管 Python 标准库涵盖了大量的功能,但还是有一些功能难以编写,又或是使用标准库来实现效率很低。这个时候就该 PyPI 上场了。PyPI 代表 Python Package Index(Python 包目录),它是任何人(包括你!)都可以上传开源 Python 包的巨大仓库,利用这些包可以扩展 Python 的功能。
如果想更方便地从互联网上获取数据,可以安装 Requests 包来获取一系列强大又好用的命令。要安装一个包,需要在命令提示符或者终端中使用 Python 的包管理器,即 pip。pip 是 pip installs packages 的递归缩写。
为什么包管理器如此重要。一个主要原因是,任何优质的包可能不仅依赖于 Python 标准库,还会依赖于 PyPI 上的其他开源包。而这些依赖项又可能会依赖其他的包,层层递进。pip 会递归地检查一个包的依赖项和子依赖项,并逐一下载安装。你还可以使用 pip 轻松地更新包,以保持各个依赖项都是最新版本。pip 让你能够坚守 DRY 原则,因为不用重新发明轮子或者复制粘贴 PyPI 上已有的包。有了 pip 和 PyPI,你就有了一套统一的机制来分发和安装依赖项——这正是 Excel 的插件所欠缺的。
1.2.3 科学计算 #
诸如 NumPy、SciPy 和 pandas 之类的科学计算库提供了一种简洁的方式来表达数学问题。
1.2.5 跨平台兼容性 #
即便在一台运行着 Windows 或者 macOS 的本地计算机上开发,在某个时候你也可能会想让代码在一台服务器或者云端上运行。服务器会通过其运算能力,让代码按计划执行,并使应用程序可以从任何地方访问。
第二章 开发环境 #
先安装好 Anaconda Python 发行版。除了安装 Python,Anaconda 还会安装 Anaconda Prompt 和 Jupyter 笔记本。它们是贯穿本书的两种关键工具。Anaconda Prompt 是一种特殊的命令提示符(用 Windows 的话来说)或者终端(用 macOS 的话来说),我们可以通过它来运行 Python 脚本和一些本书中会用到的命令行工具。Jupyter 笔记本让我们可以交互地处理数据、代码和图表,可以说它是 Excel 工作簿的强力竞争者。在体验了 Jupyter 笔记本之后,我们会安装一个强大的文本编辑器——Visual Studio Code(VS Code)。VS Code 内置了集成终端,用它来编写、执行和调试 Python 代码非常方便。

2.1 Anaconda Python 发行版 #
2.1.2 Anaconda Prompt #
Anaconda Prompt 实际上就是 Windows 中的一个命令提示符或者 macOS 中的终端,只不过它配置好了 Python 解释器和第三方包。Anaconda Prompt 是执行 Python 代码的最基本的工具,本书会大量使用它来执行 Python 脚本和各种包提供的命令行工具。

在 Windows 中,输入 dir 并按回车键。命令提示符会打印出当前所在目录的内容。
输入 cd Down 并按 tab 键。cd 代表切换目录。如果位于 home 文件夹中,那么 Anaconda Prompt 极有可能会将刚才输入的内容自动补全为 cd Downloads。
注意,如果路径以你当前所在目录中的文件夹名或文件名开始,那么你用的就是相对路径,比如 cd Downloads。如果想离开当前目录,可以输入绝对路径,比如在 Windows 中输入 cd C:\Users。
切换至父目录(上一级目录),需要输入 cd .. 然后按回车键(确保在 cd 和两点之间有一个空格)。将这个命令和目录名相结合,如果你想先返回上一级目录,然后进入 Desktop,可以输入 cd ..\Desktop。
2.1.3 Python REPL:交互式 Python 会话 #
交互式 Python 会话也被称为 REPL,意思是读取 – 求值 – 输出循环(read-eval-print loop),Python 会读取你的输入,对其求值,然后立即输出结果并等待下一次输入。
要退出 Python 会话,需要输入 quit() 并按回车键。也可以在 Windows 中按下快捷键
Ctrl+Z,然后按回车键。
2.1.4 包管理器:Conda 和 pip #
Python 的包管理器 pip,它负责下载、安装、更新和卸载 Python 包及其依赖项和子依赖项。虽然 Anaconda 也可以配合 pip 工作,但是它还有一个名为 Conda 的内置包管理器。Conda 的一大优势是不仅可以安装 Python 包,还可以安装多种版本的 Python 解释器。一言以蔽之:软件包可以为 Python 添加标准库中所没有的功能。
在使用 Anaconda 的情况下,应该尽可能地用 Conda 安装各种软件包。而 pip 只是用来安装那些在 Conda 中找不到的软件包。不然的话 Conda 可能会覆盖你用 pip 安装的包。
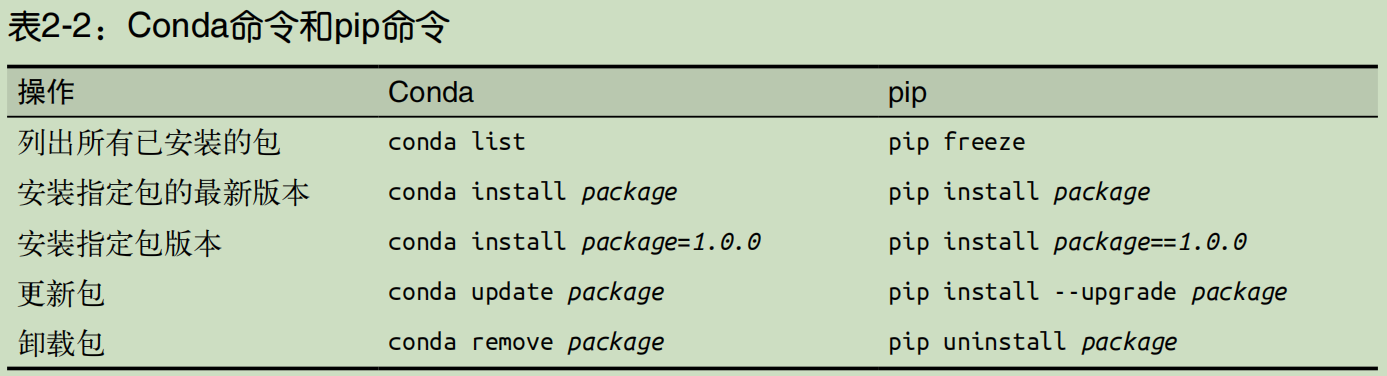
表 2-2 列出了最常用的命令。这些命令必须在 Anaconda Prompt 中输入,可以让你安装、更新和卸载第三方包。
查看安装的 Anaconda 发行版中已经安装了哪些包,可以输入以下代码:
(base)> conda list
安装 Plotly 和 xlutils,这两个包都可以在 Conda 中找到:
(base)> conda install plotly xlutils
执行这条命令之后,Conda 会向你表明它要干些什么,你需要输入 y 并按回车键表示确认。
通过 pip 来安装 pyxlsb 和 pytrends,这两个包 Conda 中没有:
(base)> pip install pyxlsb pytrends
和 Conda 不一样,pip 在你按回车键之后会立即开始安装而不需要确认。
2.1.5 Conda 环境 #
Anaconda Prompt 每行开头的 (base) 到底是什么。它是当前激活的 Conda 环境的名称。Conda 环境是一个被隔离的“Python 世界”,有着特定版本的 Python 和一系列安装好的包。为什么非要这么做呢?当你同时开发多个项目的时候,各个项目会有不同的需求:一个项目可能需要 Python 3.8 和 pandas 0.25.0,而另一个项目可能需要 Python 3.9 和 pandas 1.0.0。由于为 pandas 0.25.0 编写的代码往往需要进行修改才能用到 pandas 1.0.0 上,因此不能只更新 Python 和 pandas 而保持代码原封不动。为每个项目都配置一个 Conda 环境可以保证它们使用正确的依赖项运行。Conda 环境虽然是 Anaconda 发行版的专有概念,但虚拟环境是所有 Python 发行版的通用概念。相比之下 Conda 环境更加强大,因为它不仅可以管理多个版本的软件包,还可以轻松管理不同版本的 Python 解释器。
创建新项目时,为每个项目使用单独的 Conda 环境或者虚拟环境是很好的实践方式,这可以让你规避不同项目之间的依赖冲突。
详情可见附录 A
2.2 Jupyter 笔记本 #
在数据科学领域,人们热衷于使用 Jupyter 笔记本来运行代码。它把格式规整的可执行 Python 代码、图片和图表融合到一个交互式笔记本中,并且这个笔记本是运行在浏览器中的。Jupyter 笔记本对初学者很友好,在教学、原型开发、研究等领域极为受欢迎,极大地方便了可重现的研究。
Jupyter 笔记本可以快速准备、分析和可视化数据,这和工作簿的用例几乎相同。它已然成了 Excel 的竞争者。但和 Excel 不同,Jupyter 笔记本是用 Python 代码来完成这些工作的,而不是用鼠标在 Excel 中点来点去。Jupyter 笔记本的另一个优势是,它不会把数据和业务逻辑混在一起。Jupyter 笔记本会负责代码和图表,使用来自外部 CSV 文件或者数据库中的数据。Jupyter 笔记本在本地和远程服务器上都可以运行,一般来说,服务器要比本地机器性能更强,它可以在无人值守的情况下运行代码。
2.2.1 运行 Jupyter 笔记本 #
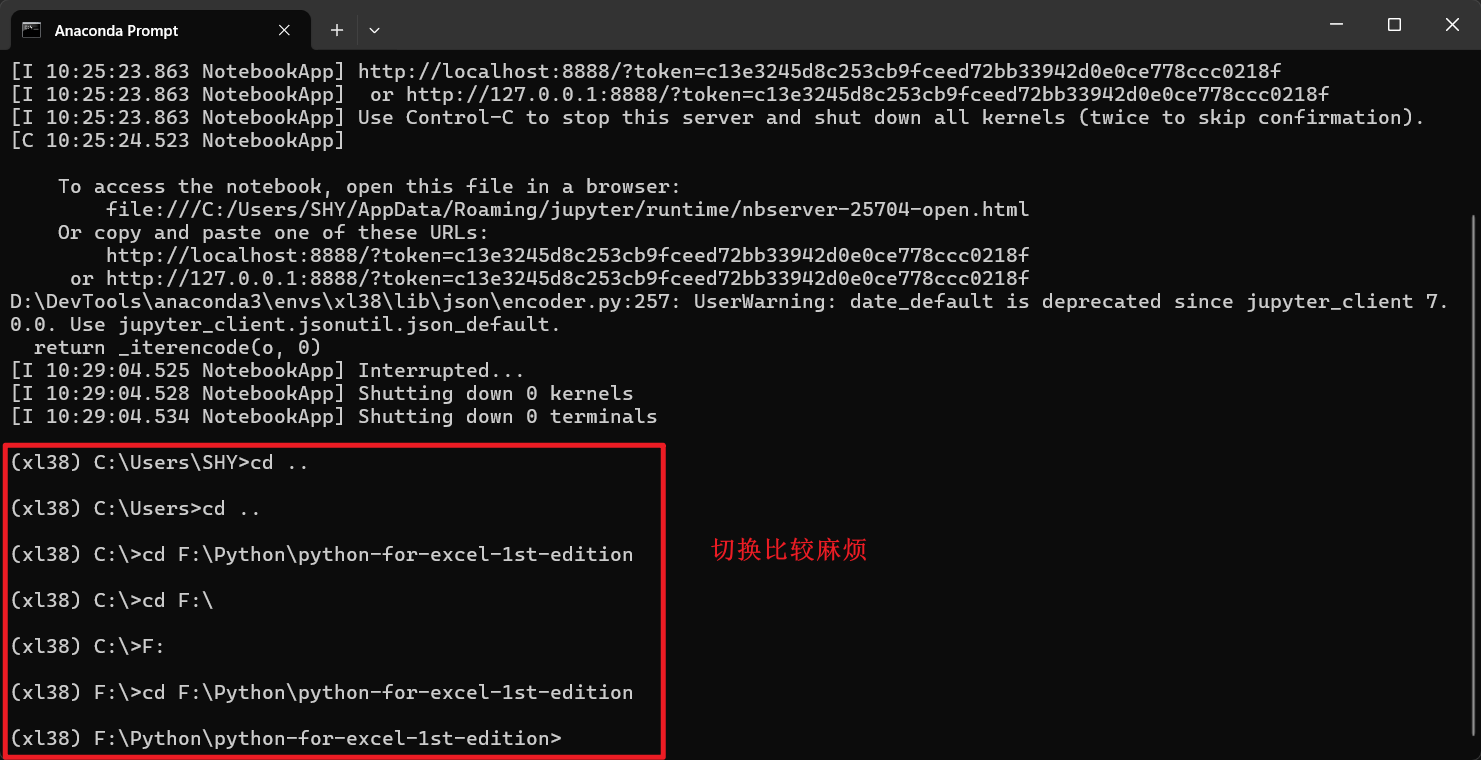
在 Anaconda Prompt 中,切换至配套代码库所在目录,这里使用创建的虚拟环境 xl38,然后启动 Jupyter 笔记本服务器:
(xl38)> cd ..
(xl38)> cd ..
(xl38)> F:
(xl38)> cd F:\Python\python-for-excel-1st-edition
(xl38)> jupyter notebook
打开的 Jupyter 仪表板会显示执行命令时所在目录中的文件。在 Jupyter 仪表板的右上方,点击新建,在下拉列表中选择 xl38,这里需要激活连接新建的虚拟环境 xl38(具体可见文档:Python 开发环境安装流程.md 中的 Jupyter 代码编辑器的虚拟环境连接 Jupyter),过程如下:
(xl38) C:\Users\SHY>pip install ipykernel -i https://pypi.tuna.tsinghua.edu.cn/simple
(xl38) C:\Users\SHY>python -m ipykernel install --user --name=xl38
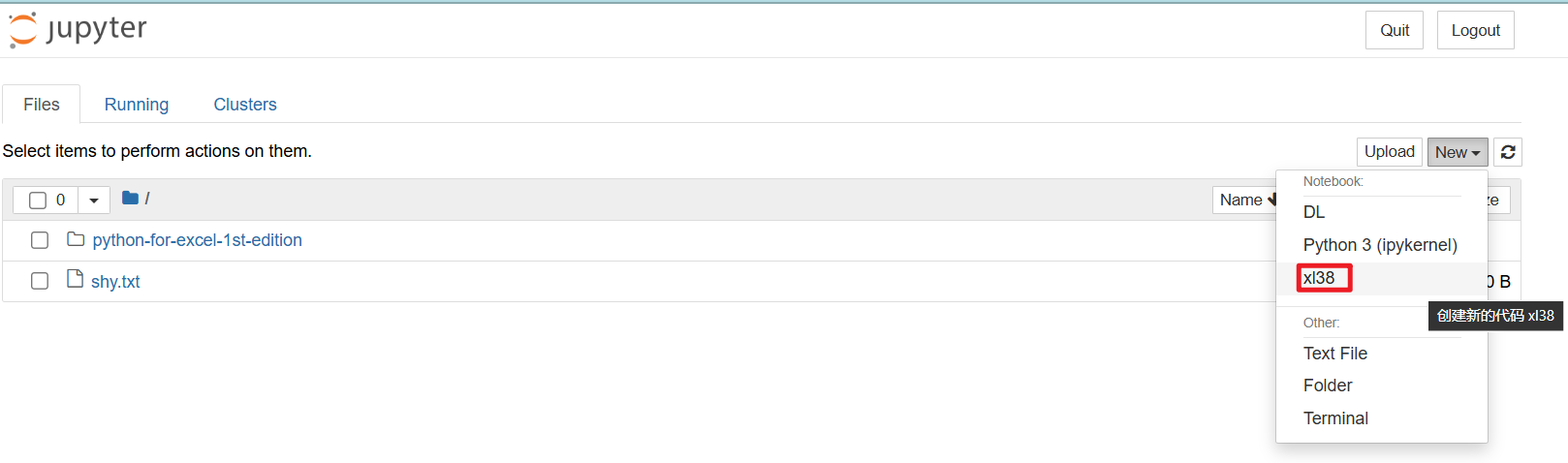
浏览器会为你的第一个空白笔记本打开新的标签页:

点击 Jupyter logo 旁边的 Untitled,为工作簿取一个更有意义的名字,比如 first_notebook。
2.2.2 笔记本单元格 #
输入 3 + 4,然后点击上面菜单栏中的运行按钮,或者用更方便的快捷键:Shift+ 回车。单元格中的代码将会执行,并把结果输出到单元格下方,然后跳到下一个单元格。由于目前我们只有一个单元格,因此笔记本会在下面插入一个空白单元格。现在再仔细看一下,当单元格正在计算时,会显示 In [*];在计算完成时,星号就变成了数字,也就是 In [1]。在这个单元格下方你会看到对应的输出单元格,而且和输入单元格有相同的编号:Out [1]。每当你运行一个单元格,编号就会加 1,这个编号可以帮助你识别单元格执行的顺序。

**注意:**如果单元格的最后一行返回了一个值,那么它会自动输出到 Jupyter 笔记本的 Out [ ] 单元格中。然而,如果你使用的是 print 函数或者发生了异常,则相应的输出会直接显示在 In 单元格下方而没有 Out [ ] 标签。
单元格有不同的类型,我们需要关注以下两种。
1、代码:默认类型。需要执行 Python 代码时就会用到它。
2、Markdown:Markdown 是一种格式化语法,它使用标准的文本字符来格式化文本。可以用它在笔记本中添加格式规整的解释和说明。
要把单元格的类型切换为 Markdown,先选中单元格,然后在单元格模式下拉菜单中选 Markdown,
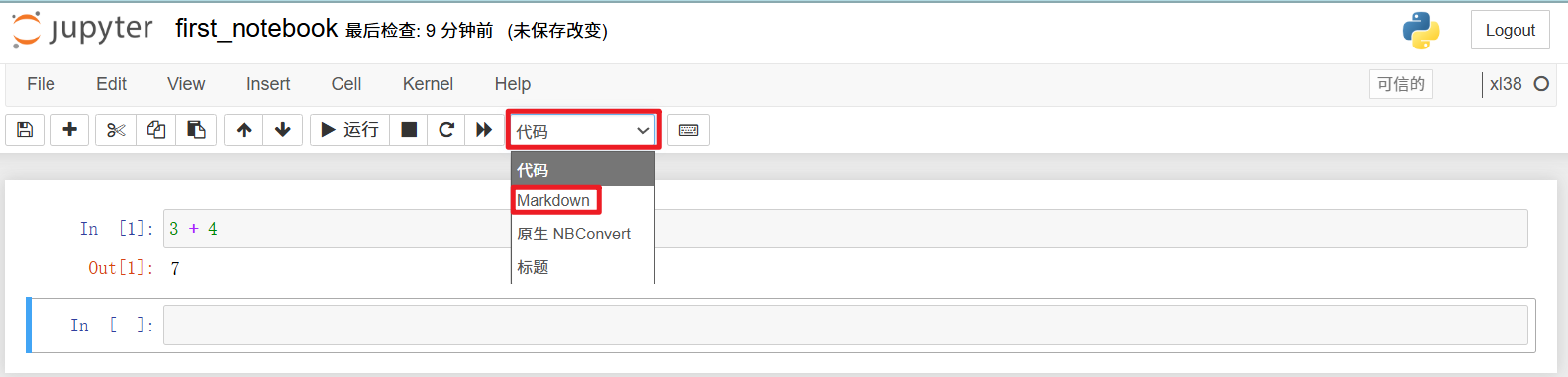
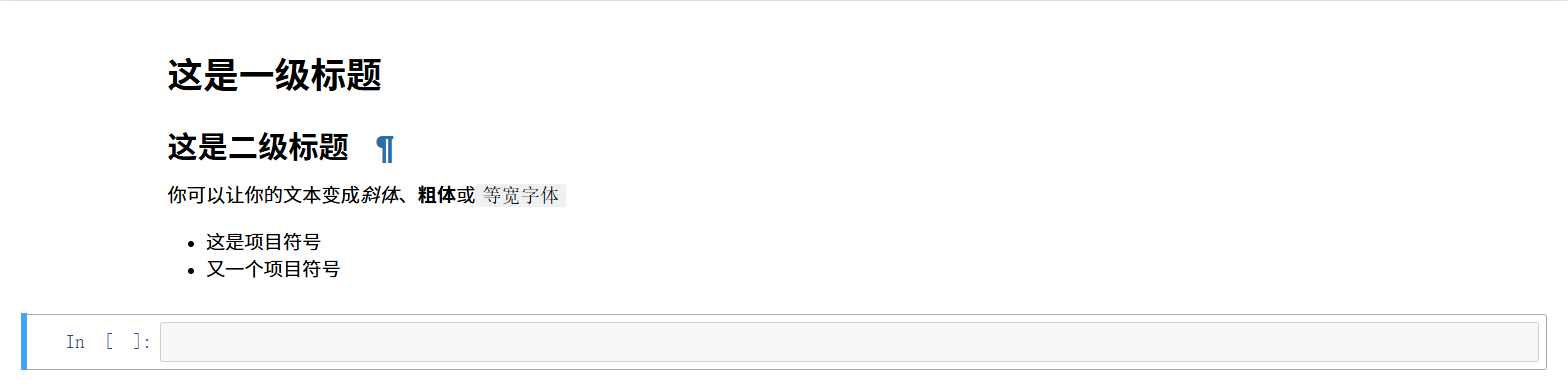
在将一个空单元格切换为 Markdown 单元格后,输入下列文本,这是对 Markdown 语法规则的介绍
# 这是一级标题
## 这是二级标题
你可以让你的文本变成*斜体*、**粗体**或`等宽字体`
* 这是项目符号
* 又一个项目符号
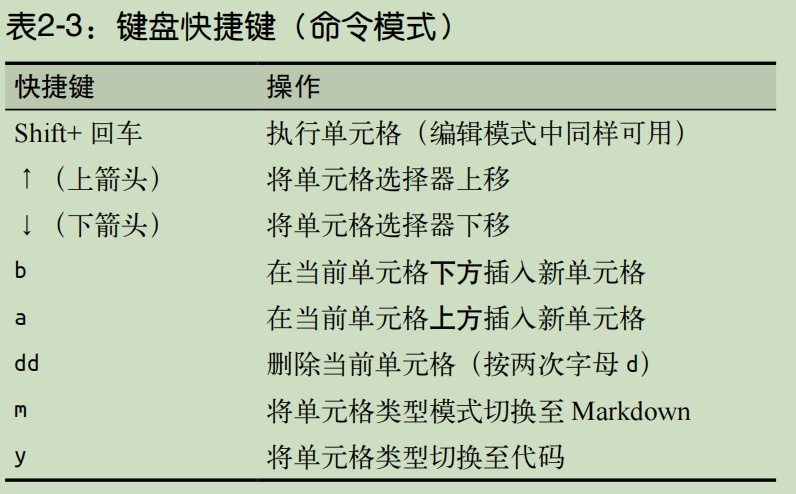
按下快捷键 Shift+ 回车之后,这段文本会被渲染成格式规整的 HTML。Markdown 单元格还可以添加图片、视频或公式。

2.2.3 编辑模式与命令模式 #
当和 Jupyter 笔记本中的单元格互动时,你要么处于编辑模式(editing mode),要么处于命令模式(command mode)。
编辑模式:点击一个单元格以启动编辑模式。被选中的单元格边缘会变成绿色,单元格中的光标也会开始闪烁。除了点击单元格,还可以在选中单元格时按回车键。
命令模式:要切换至命令模式,需要按下 Esc 键。被选中的单元格边缘会变成蓝色且不会出现光标。
2.2.4 执行顺序很重要 #
假设你的笔记本中有下面这样几个单元格,从上往下执行:
In [2]: a = 1
In [3]: a
Out[3]: 1
In [4]: a = 2

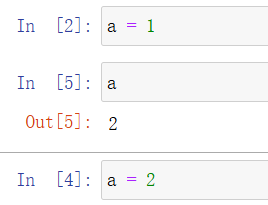
单元格 Out[3] 会按照预期输出 1。然而,如果你回去再一次执行 In[3],就会得到下面的结果:
In [2]: a = 1
In [5]: a
Out[5]: 2
In [4]: a = 2
2.2.5 关闭 Jupyter 笔记本 #
每个笔记本都在一个独立的 Jupyter 内核中运行。内核是运行单元格中 Python 代码的“引擎”。每个内核都会消耗操作系统提供的 CPU 和 RAM 资源。在关闭笔记本时,还需要关闭它的内核,以便内核所占用的资源可以被其他任务重用——从而防止系统变慢。
最简单的方法是选择菜单中的“文件 > 关闭”。如果只是关闭了浏览器标签页,那么内核并不会自动关闭。另外,在 Jupyter 仪表板中,也可以从运行标签页中关闭正在运行的笔记本。
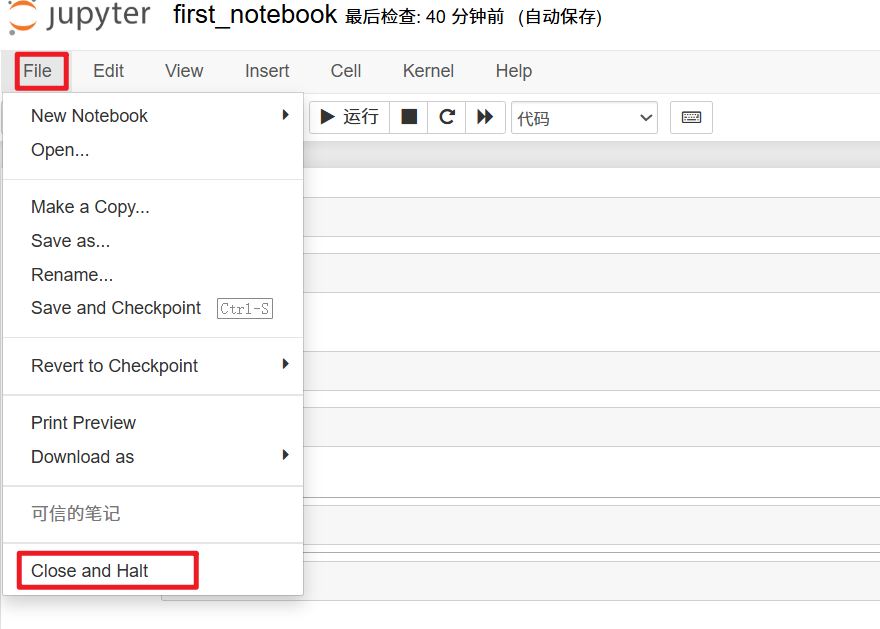
要关闭整个 Jupyter 服务器,可以点击 Jupyter 仪表板右上方的退出按钮(logout)。如果已经关闭了浏览器,可以在运行笔记本服务器的 Anaconda Prompt 中按两次快捷键 Ctrl+C,或者连同 Anaconda Prompt 一起关闭。
2.3 VS Code #
安装并配置 VS Code,它是微软开发的一个免费且开源的文本编辑器。
Jupyter 笔记本虽然对于研究、教学和实验这类互动型的工作流程来说很好用,但是如果想编写针对生产环境的 Python 脚本(这类脚本用不到笔记本的可视化功能),Jupyter 笔记本并非理想之选。对于一些涉及大量文件和多位开发者的复杂项目,Jupyter 笔记本也不是那么好用。
理论上来讲,可以使用任何文本编辑器(哪怕是记事本也行),但实际上你需要的是一个可以“理解”Python 的编辑器。这样的编辑器至少应该有如下特性。
1、语法高亮:编辑器会为具有不同语义(函数、字符串、数字,等等)的单词赋予不同的颜色,从而使得代码更容易阅读和理解。
2、自动补全:自动补全(autocomplete),或者用微软的话来讲叫智能感知(intelliSense),可以为文本组件提供建议,以便你少打字、少打错字。
VS Code 自 2015 年发布以来就深受开发者喜爱,其融合了纯文本编辑器和全功能 IDE:VS Code 是一个迷你 IDE,囊括了编程所需要的所有工具。除此之外,它还具有如下特性。
1、跨平台:VS Code 可以在 Windows、macOS 和 Linux 中运行,也有像 GitHub Codespaces 这样的云托管版本。
2、集成工具:VS Code 内置调试器,支持 Git 版本控制,还有可以用作 Anaconda Prompt 的集成终端。
3、扩展:包括 Python 支持在内的其他所有功能,都可以以扩展的形式一键安装。
4、轻量:根据操作系统的不同,VS Code 的安装包仅有 50MB~100MB 大小。
VS Code 和 Visual Studio
不要把 VS Code 和名为 Visual Studio 的 IDE 搞混了!虽然也可以用 Visual Studio 来进行 Python 开 发 [Visual Studio 有 PTVS(Python Tools for Visual Studio,适用于 Visual Studio 的 Python 工具)],但是需要安装很多东西。传统上 Visual Studio 是用来做 .NET 语言(如 C#)开发的。
2.3.1 安装和配置 #
下载官网:Visual Studio Code - Code Editing. Redefined
安装的时候注意安装位置,避免安装到 C 盘。VS Code 确实是一个开箱即用的优秀文本编辑器,但是要让它完美配合 Python,还需要进行一些配置。点击活动栏上的扩展图标,然后搜索 Python。安装作者显示为微软(Microsoft)的官方 Python 插件。待其安装完成之后,可以点击需要重新加载按钮来完成安装。或者也可以完全重启 VS Code。
命令面板:按下 F1 键或者快捷键:Ctrl+Shift+P(Windows 系统)或者 Command-Shift-P(macOS 系统),可以打开命令面板。如果对某些东西拿不准,你首先就应该想到命令面板。VS Code 所有功能的快捷入口都在其中。
Windows 中,打开命令面板,输入 default profile。选择“终端:选择默认配置文件”这一项,然后按回车键。在下拉菜单中,选择命令提示符并按回车键确认。我们需要这样设置,以便 VS Code 正常激活 Conda 环境。
2.3.2 执行 Python 脚本 #
虽然可以从 Windows 的开始菜单或者 macOS 的启动台打开 VS Code,但是直接从 Anaconda Prompt 中打开会更快——可以直接用 code 命令启动 VS Code。接下来,打开一个新的 Anaconda Prompt,通过 cd 命令将目录切换到你希望进行操作的地方,然后让 VS Code 打开当前目录(用点表示):
(base) C:\Users\SHY>conda activate xl38
(xl38) C:\Users\SHY>cd ..
(xl38) C:\Users>cd ..
(xl38) C:\>D:
(xl38) D:\>cd D:\DevTools\Jupyter\python-for-excel-1st-edition
(xl38) D:\DevTools\Jupyter\python-for-excel-1st-edition>
以这种方式启动 VS Code 可以让活动栏中的资源浏览器自动显示启动目录中的内容。
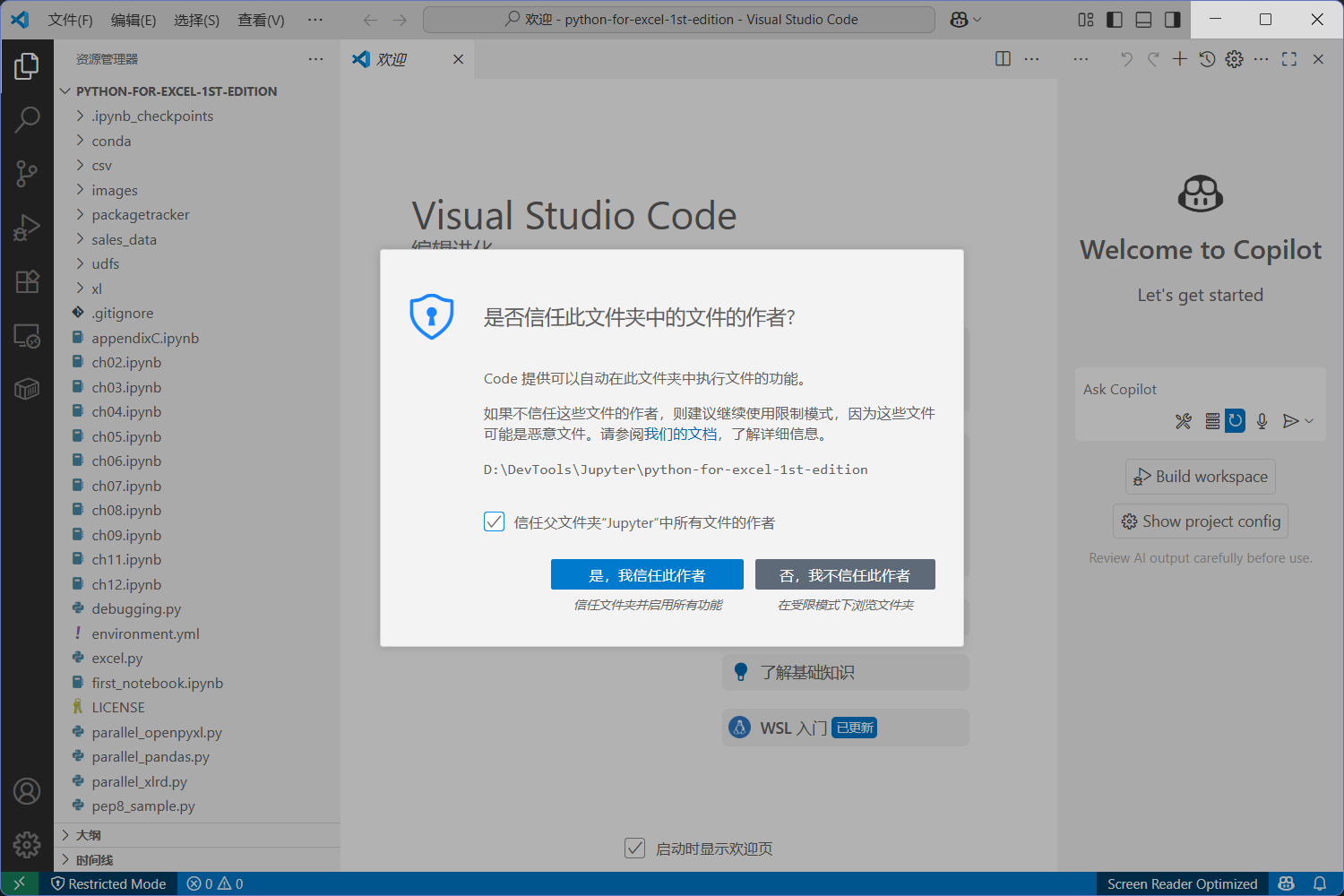
把鼠标悬停在活动栏的资源管理器中的文件上时,会看到新建文件按钮。点击新建文件,取名为 hello_world.py,然后按回车键。当文件在编辑器中打开之后,输入下面这行代码:
print("hello world!")
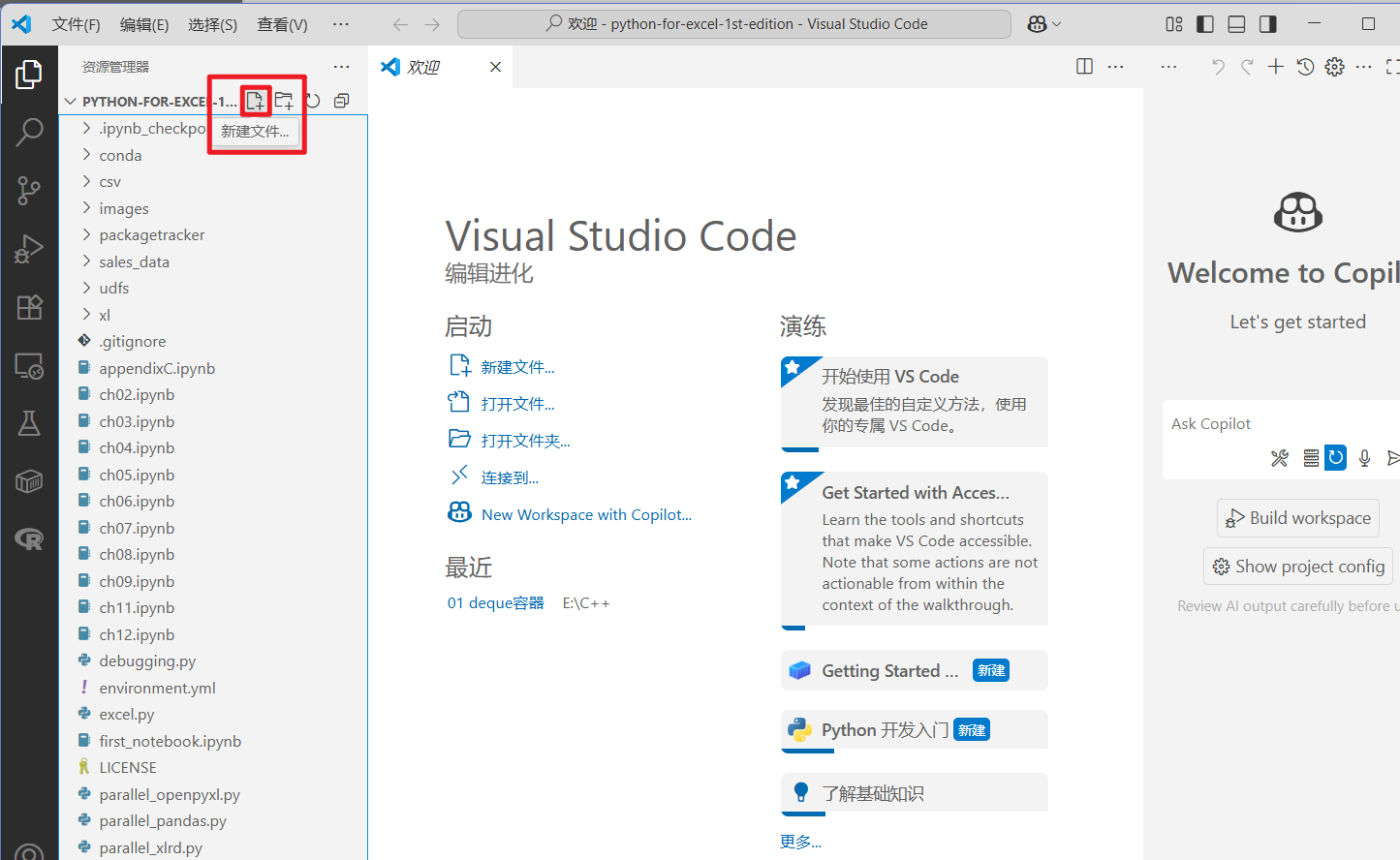
状态栏中,应该可以看到 Python 的版本,比如“Python 3.8.5 64-bit (conda)”。如果点一下,命令面板会显示让你选择一个不同的 Python 解释器(如果你有好几个的话),也包括不同的 Conda 环境。
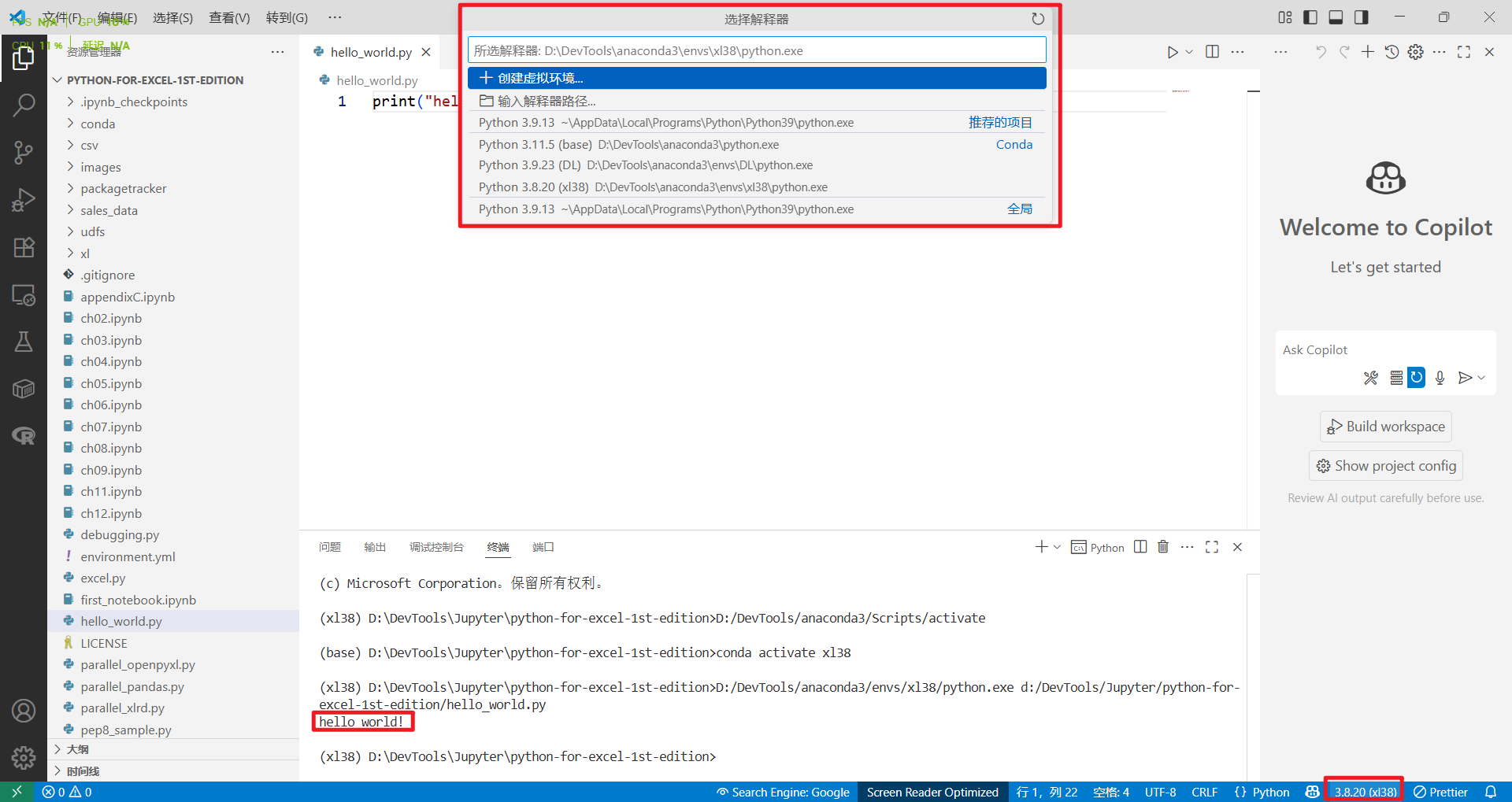
在执行脚本之前,一定要先保存。在 Windows 中可以按快捷键 Ctrl+S 进行保存。
在 VS Code 中,可以通过 Anaconda Prompt 运行,也可以直接点运行按钮。当你要执行一个服务器上的脚本时,可能更多地还是从 Anaconda Prompt 中执行,所以有必要知道具体如何操作。
Anaconda Prompt:打开 Anaconda Prompt,将 cd 放入脚本所在的文件夹中,按如下方式运行脚本:
(xl38)> cd cd D:\DevTools\Jupyter\python-for-excel-1st-edition
(xl38)> python hello_world.py
hello world!
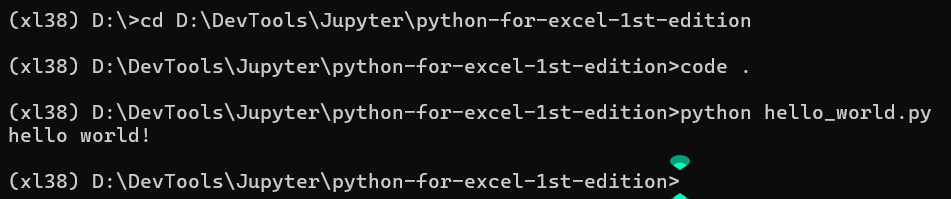
注意,如果你当前不在 Python 文件所在的目录,则需要使用完整路径。
1、VS Code 中的 Anaconda Prompt:
不必为了使用 Anaconda Prompt 而从 VS Code 中切换出去。在 VS Code 中可以直接通过快捷键 Ctrl+` 或者“查看 > 终端”菜单项显示集成终端。由于集成终端会在项目所在文件夹中打开,因此也不需要切换目录
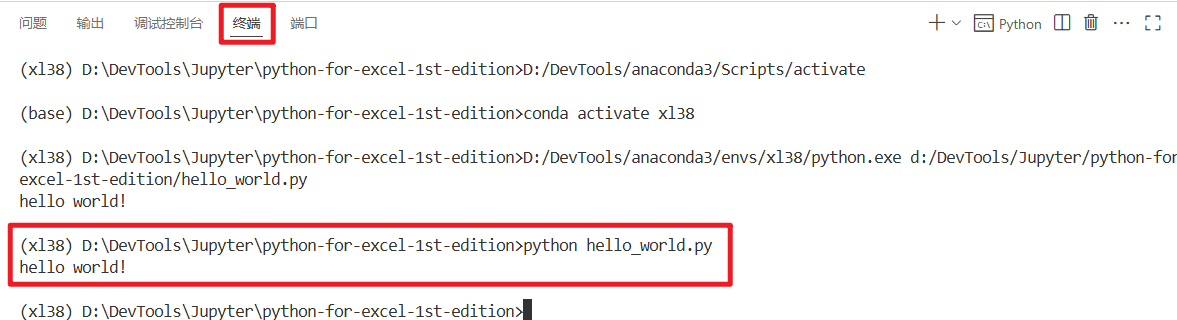
2、VS Code 中的运行按钮
在 VS Code 中,有一种无须使用 Anaconda Prompt 也能运行代码的简单方法。在编辑 Python 文件时,你会在右上方看到一个播放图标,这就是运行文件按钮。点击这个按钮会自动在底部打开终端并运行代码。

3、在 VS Code 中打开文件
当你在资源管理器(位于活动栏)中单击一个文件时,VS Code 会有一些令人意外的默认行为。单击文件后,文件会以预览模式打开,意思就是说如果没有对这个文件进行更改,那么你下一次单击打开的文件会替换掉这个文件的标签页。如果想关掉单击操作的这种行为(变成单击选定文件,双击打开),可以在“首选项 > 设置”中(或者用快捷键,在 Windows 中是 Ctrl+,,在 macOS 中是 Command-,)将“工作台 >‘List: Open Mode’”设置为“doubleClick”。
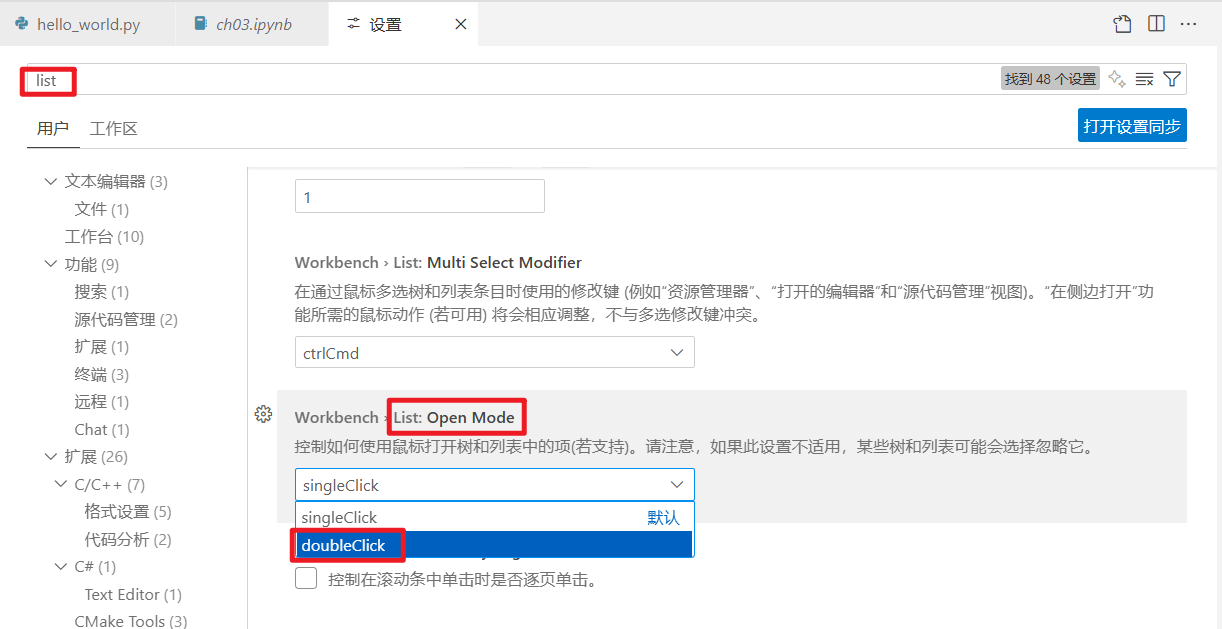
拓展:


第三章 Python 入门 #
本章首先会介绍 Python 的基本数据类型,比如整型和字符串。然后会介绍 Python 的核心概念——索引和切片,使你可以访问一个序列的指定元素。接下来会讲到列表和字典等数据结构,它们可以保存多个对象。之后会介绍 Python 中的控制流:if 语句、for 循环和 while 循环。紧接着是函数和模块的相关知识,它们可以用来组织和架构你的代码。最后会展示应该如何正确格式化 Python 代码。
3.1 数据类型 #
最常用的数据类型有整型、浮点型、布尔值和字符串。要理解什么是数据类型,需要先解释一下什么是对象。
3.1.1 对象 #
在 Python 中,一切皆对象(object)。数字、字符串、函数,以及我们会在本章中见到的其他所有东西,它们都是对象。通过提供一系列变量和函数,对象可以让复杂的东西简单化。先来看看变量和函数。
1、变量:
在 Python 中,变量(variable)是通过等号给对象赋予的一个名字。 Python 中,可以通过给变量赋值一个新的对象来改变变量的类型。这种行为被称作动态类型:
In [2]: a = 3
print(a)
a = "three"
print(a)
3
three
Python 是区分大小写的,因此 a 和 A 是不同的变量。变量名必须遵守下列规则:
• 必须以字母或下划线开头;
• 只能由字母、数字和下划线组成。
2、函数
要调用一个函数,需要在函数名后跟上一对圆括号,并在圆括号中提供参数,和数学记法几乎一模一样:
function_name(argument1, argument2, ...)
3、属性和方法
谈到对象时,变量被称作属性(attribute)1 ,函数被称作方法(method)。你可以通过属性来访问对象的数据,而方法可以用来执行某种操作。你可以通过点号来访问属性和方法,比如 myobject.attribute 和 myobject.method()。
如果你在写一个赛车游戏,那么很可能需要表示车的对象。car 对象应该有一个 speed 属性,这样你就可以通过 car.speed 来获取车辆的当前速度。或许还可以通过调用加速方法 car.acc.accelerate(10) 来让车辆加速,即让车速增加到每小时 10 英里。
对象的类型及其行为是由类(class)定义的,因此在前面的例子中,你可能需要编写一个 Car 类。从 Car 类构造 car 对象的过程叫作实例化(instantiation)。要实例化一个对象,需要像调用函数那样去调用类:car = Car()。
3.1.2 数值类型 #
int 和 float 分别表示整数(integer)和浮点数(floating-point number)。通过内置的 type 函数可以获得指定对象的类型:
In [3]: type(4)
Out[3]: int
In [4]: type(4.4)
Out[4]: float
强制让一个数字成为 float 类型而不是 int 类型,可以在后面加一个小数点,或者使用 float 构造器:
In [5]: type(4.)
Out[5]: float
In [6]: float(4)
Out[6]: 4.0
对于整型也是一样的,int 构造器可以将一个 float 值转换为 int。如果小数部分不为零,那么转换时会直接舍去。
In [7]: int(4.9)
Out[7]: 4
Excel 单元格永远保存的是浮点数:从 Excel 单元格读取数字的时候,可能需要先把 float 转换为 int,然后才能把它传给一个需要整型参数的函数。原因是即使 Excel 显示的是整数,但在背后它总是以浮点数形式存储。
3.1.3 布尔值 #
Python 中,布尔类型只有 True 和 False 两种取值,Python 中的布尔运算符 and、or 和 not 全是小写形式。每个 Python 对象都可以被视作 True 或 False。大部分的对象会被视作 True,但 None、False、0 或空数据类型 [ 比如空字符串(下一节中会讲到字符串)] 会被视作 False。
None 是一个内置的常量,按照官方文档的说法,它代表“没有值”(the absence of a value)。如果一个函数没有显式地返回值,那么它实际上返回的就是 None。None 可以用来表示 Excel 中的空单元格。
3.1.4 字符串 #
Python 中的字符串既可以用双引号(")来表示,也可以用单引号(’)来表示。唯一的要求是字符串的首尾必须是同一种引号。可以用 + 来拼接字符串,或者用 * 来重复字符串的内容。如果发现字符串的内容还是需要转义,可以用反斜杠来转义字符:
In [31]: print("Don't wait! " + 'Learn how to "speak" Python.')
Don't wait! Learn how to "speak" Python.
In [32]: print("It's easy to \"escape\" characters with a leading \\.")
It's easy to "escape" characters with a leading \.
当字符串中包含变量的值时,通常可以使用 f 字符串(f-string,格式化字符串字面量,formatted string literal 的缩写)来处理。
In [33]: # 注意Python如何在一行中为多个变量赋予多个值
first_adjective, second_adjective = "free", "open source"
f"Python is {first_adjective} and {second_adjective}."
Out[33]: 'Python is free and open source.'
转换大小写:
In [34]: "PYTHON".lower()
Out[34]: 'python'
In [35]: "python".upper()
Out[35]: 'PYTHON'
获取帮助:在 Jupyter 笔记本中,敲入对象后面的点之后按 Tab 键,比如 “python”.
3.2 索引和切片 #
索引和切片让你可以访问一个序列的指定元素。
3.2.1 索引 #
Python 的索引从 0 开始,意思就是说序列的第一个元素通过 0 来引用。负索引从 -1 开始,你可以用负索引从序列末端引用元素。
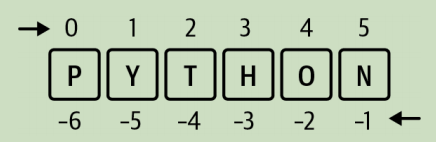
索引的语法如下:
sequence[index]
访问字符串的指定元素:
In [36]: language = "PYTHON"
In [37]: language[0]
Out[37]: 'P'
In [38]: language[1]
Out[38]: 'Y'
In [39]: language[-1]
Out[39]: 'N'
In [40]: language[-2]
Out[40]: 'O'
3.2.2 切片 #
如果你想从一个序列中获取一个以上的元素,就要用到切片(slicing)语法:
sequence[start:stop:step]
Python 使用的是左闭右开区间,意思是切片区间包含 start,但不包含 stop。如果省略了 start 或者 stop,则切片会分别包含从头开始或者从末尾开始的所有元素。step 决定了切片的方向和步长。如果令步长为 2,那么切片就会从左到右每两个元素取一个值;如果令步长为 -3,则切片会从右到左每 3 个元素取一个值。默认步长为 1:
In [41]: language[:3] # 同language[0:3]
Out[41]: 'PYT'
In [42]: language[1:3]
Out[42]: 'YT'
In [43]: language[-3:] # 同language[-3:6]
Out[43]: 'HON'
In [44]: language[-3:-1]
Out[44]: 'HO'
In [45]: language[::2] # 每两个元素取一个
Out[45]: 'PTO'
In [46]: language[-1:-4:-1] # 负步长从右到左
Out[46]: 'NOH'
Python 也可以将多次索引和切片操作串联起来。如果你想获得最后 3 个字符中的第二个,可以像下面这样做:
In [47]: language[-3:][1]
Out[47]: 'O'
上述代码和 language[-2] 是等价的,连续索引并不会简单到哪儿去。但是在索引和切片列表的时候,连续索引会显得更有条理一些。
3.3 数据结构 #
Python 提供了强大的数据结构以便于处理对象集合。本节会介绍列表、字典、元组和集合。虽然每种数据结构有各自的特点,但它们有一个共同特点,即都能存储多个对象。
3.3.1 列表 #
列表(list)可以存储不同数据类型的多个对象。用途广泛,可以随时使用。创建列表的语法如下:
[element1, element2, ...]
实例,下面是两个列表,一个保存了一些 Excel 文件的名称,另一个保存了几个数字:
In [48]: file_names = ["one.xlsx", "two.xlsx", "three.xlsx"]
numbers = [1, 2, 3]
和字符串一样,列表也可以用加号进行拼接。下面的代码还体现了列表的一个特性,那就是它可以保存不同类型的对象:
In [49]: file_names + numbers
Out[49]: ['one.xlsx', 'two.xlsx', 'three.xlsx', 1, 2, 3]
列表也是对象,也可以包含其他列表作为元素。我称之为嵌套列表(nested list):
In [50]: nested_list = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
把这种嵌套列表写成多行,你就会发现列表可以很好地表示矩阵和工作表单元格。注意,这些方括号会隐式地让代码跨行(参见“跨行”)。通过索引和切片,你可以获得想要的任何元素。
In [51]: cells = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
In [52]: cells[1] # 第二行
Out[52]: [4, 5, 6]
In [53]: cells[1][1:] # 第二行的第二列和第三列
Out[53]: [5, 6]
更改列表中的元素:
In [56]: users = ["Linda", "Brian"]
In [57]: users.append("Jennifer") # 最常用的操作是向列表末尾追加元素
users
Out[57]: ['Linda', 'Brian', 'Jennifer']
In [58]: users.insert(0, "Kim") # 在索引0处插入"Kim"
users
Out[58]: ['Kim', 'Linda', 'Brian', 'Jennifer']
要删除一个元素,可以使用 pop 或者 del。pop 是一个方法,而 del 是一种 Python 语句:
In [59]: users.pop() # 在默认情况下,移除并返回最后一个元素
Out[59]: 'Jennifer'
In [60]: users
Out[60]: ['Kim', 'Linda', 'Brian']
In [61]: del users[0] # del会移除指定索引处的元素
可以对列表进行以下操作:
In [62]: len(users) # 长度
Out[62]: 2
In [63]: "Linda" in users # 检查users是否包含"Linda"
Out[63]: True
In [64]: print(sorted(users)) # 返回新的排好序的列表
print(users) # 原列表保持不变
['Brian', 'Linda']
['Linda', 'Brian']
In [65]: users.sort() # 对原列表进行排序
users
Out[65]: ['Brian', 'Linda']
也可以把 len 和 in 用在字符串上:
In [66]: len("Python")
Out[66]: 6
In [67]: "free" in "Python is free and open source."
Out[67]: True
要访问列表中的元素,可以通过元素的**位置(索引)**来引用一个元素——但并非任何时候都能知道元素的位置。
3.3.2 字典 #
字典(dictionary)是键到值的映射。你会经常遇到键 – 值对。创建字典最简单的方法如下:
{key1: value1, key2: value2, ...}
和索引一样,键也被放在方括号中。下面的代码中,一对货币(键)映射到了汇率(值):
In [68]: exchange_rates = {"EURUSD": 1.1152,
"GBPUSD": 1.2454,
"AUDUSD": 0.6161}
In [69]: exchange_rates["EURUSD"] # 访问EURUSD的汇率
Out[69]: 1.1152
下面的代码展示了如何修改既存的值以及添加新的键 – 值对:
In [70]: exchange_rates["EURUSD"] = 1.2 # 修改已经存在的值
exchange_rates
Out[70]: {'EURUSD': 1.2, 'GBPUSD': 1.2454, 'AUDUSD': 0.6161}
In [71]: exchange_rates["CADUSD"] = 0.714 # 添加新的键–值对
exchange_rates
Out[71]: {'EURUSD': 1.2, 'GBPUSD': 1.2454, 'AUDUSD': 0.6161, 'CADUSD': 0.714}
合并两个或多个字典的最简单的办法是将字典解包(unpack)后再合并到一个新的字典中。在字典前加上两个星号就可以进行解包。如果第二个字典包含第一个字典中的键,那么第一个字典中对应的值会被覆盖。
In [72]: {**exchange_rates, **{"SGDUSD": 0.7004, "GBPUSD": 1.2222}}
Out[72]: {'EURUSD': 1.2,
'GBPUSD': 1.2222,
'AUDUSD': 0.6161,
'CADUSD': 0.714,
'SGDUSD': 0.7004}
Python 3.9 引入了管道符号 作为专门的字典合并运算符。上面的表达式可以简化成如下代码:
exchange_rates | {"SGDUSD": 0.7004, "GBPUSD": 1.2222}
get 方法可以在键不存在时返回一个默认值:
In [75]: # currencies[100]会引发异常
# 除了100,还可以尝试任何不存在的键
currencies.get(100, "N/A")
Out[75]: 'N/A'
3.3.3 元组 #
元组(tuple)和列表类似,只不过它们是不可变的(immutable):一旦被创建,它们的元素就无法被修改。虽然很多时候元组和列表可以互换使用,但对于那些在整个程序中都不会发生改变的集合来说,元组是不二之选。元组是通过多个被逗号分隔的值创建的:
mytuple = element1, element2, ...
使用圆括号通常更易于阅读:
In [76]: currencies = ("EUR", "GBP", "AUD")
可以使用访问数组的方法来访问元组,只是不能修改元组的元素。拼接元组会在“暗地里”创建一个新的元组,然后再把新元组绑定到你的变量上:
In [77]: currencies[0] # 访问第一个元素
Out[77]: 'EUR'
In [78]: # 拼接元组会返回一个新元组
currencies + ("SGD",)
Out[78]: ('EUR', 'GBP', 'AUD', 'SGD')
附录 C 中会解释可变对象和不可变对象之间的区别。
3.3.4 集合 #
集合(set)是一种没有重复元素的集合(collection)。你自然可以把集合用于集合论的运算中,但在实践中它们经常被用于列表去重或者元组去重。使用花括号创建集合:
{element1, element2, ...}
要对列表或者元组进行去重,可以像下面这样使用 set 构造器:
In [79]: set(["USD", "USD", "SGD", "EUR", "USD", "EUR"])
Out[79]: {'EUR', 'SGD', 'USD'}
还可以进行像交集和并集之类的集合论运算:
In [80]: portfolio1 = {"USD", "EUR", "SGD", "CHF"}
portfolio2 = {"EUR", "SGD", "CAD"}
In [81]: # 同 portfolio2.union(portfolio1)
portfolio1.union(portfolio2)
Out[81]: {'CAD', 'CHF', 'EUR', 'SGD', 'USD'}
In [82]: # 同 portfolio2.intersection(portfolio1)
portfolio1.intersection(portfolio2)
Out[82]: {'EUR', 'SGD'}
回顾一下刚刚认识的 4 种数据结构,使用前面用过的字面量(literal)记法。另外,列出它们的构造器。和字面量一样,构造器可以创建对应的数据结构,并且通常用于数据结构之间的相互转换。例如,要把元组转换为列表,可以执行以下操作:
In [83]: currencies = "USD", "EUR", "CHF"
currencies
Out[83]: ('USD', 'EUR', 'CHF')
In [84]: list(currencies)
Out[84]: ['USD', 'EUR', 'CHF']

3.4 控制流 #
介绍 if 语句、for 循环和 while 循环。if 只会在满足特定条件时执行特定的代码,for 循环和 while 循环会反复执行代码块中的代码。
3.4.1 代码块和 pass 语句 #
代码块(code block)界定了一段源代码,这段代码会用于一些特定的目的。在 Python 中,代码块通过缩进来体现,而不像包括 VBA 在内的大部分编程语言那样——使用花括号。这就是所谓的有特殊含义的空白(significant white space)。Python 社区坚持使用 4 个空格作为缩进,不过你通常只需要敲一次 Tab 键就行了。Jupyter 笔记本和 VS Code 都会自动将 Tab 键转换为 4 个空格。代码块的前一行总是会以冒号结尾。一旦某一行没有被缩进,代码块就自然结束了。
3.4.2 if 语句和条件表达式 #
在 Python 中,if 语句本身不需要任何的圆括号。要检查一个值是否为 True,并不需要显式地写这样一个表达式。
条件表达式(conditional expression)或者三元运算符(ternary operator)可以以一种更紧凑的形式编写 if/else 语句:
In [88]: is_important = False
print("important") if is_important else print("not important")
not important
3.4.3 for 循环和 while 循环 #
for 循环会对一个序列 [ 比如列表、元组、字符串(记住,字符串就是字符的序列)] 进行迭代。
In [89]: currencies = ["USD", "GBP", "AUD"]
for currency in currencies:
print(currency)
USD
GBP
AUD
在 Python 中,如果你在 for 循环中需要一个计数器变量,那么可以用内置的 range 函数和enumerate 函数。先来看看 range,它会提供一连串的数字。你可以只提供一个 stop 参数,也可以同时提供 start 参数和 stop 参数,还可以提供一个可选的 step 参数。和切片类似,range 产生的区间包含 start,但不包含 stop,step 决定了步长,默认为 1:
range(stop)
range(start, stop, step)
range 会延迟求值,意思就是说只要你不明确要求求值,它就不会产生指定的序列:
In [90]: range(5)
Out[90]: range(0, 5)
将 range 转换为列表可以解决这个问题:
In [91]: list(range(5)) # stop参数
Out[91]: [0, 1, 2, 3, 4]
In [92]: list(range(2, 5, 2)) # start、stop和step 3个参数
Out[92]: [2, 4]
不过大部分时候没必要把 range 包装成一个列表:
for i in range(3):
print(i)
# 输出结果
0
1
2
如果在迭代序列时需要一个计数器变量,那么可以使用 enumerate。它会返回一系列 (index, element) 元组。 在默认情况下,索引从 0 开始,每次循环加 1。在循环中可以这样使用 enumerate:
for i, currency in enumerate(currencies):
print(i, currency)
# 输出结果
0 USD
1 GBP
2 AUD
在元组和集合中进行循环与在列表中类似。在字典中进行循环时,Python 会按照键进行循环:
exchange_rates = {"EURUSD": 1.1152,
"GBPUSD": 1.2454,
"AUDUSD": 0.6161}
for currency_pair in exchange_rates:
print(currency_pair)
# 输出结果
EURUSD
GBPUSD
AUDUSD
items 方法可以以元组的形式同时获得键和对应的值:
for currency_pair, exchange_rate in exchange_rates.items():
print(currency_pair, exchange_rate)
# 输出结果
EURUSD 1.1152
GBPUSD 1.2454
AUDUSD 0.6161
break 语句可以跳出循环:
for i in range(15):
if i == 2:
break
else:
print(i)
# 输出结果
0
1
可以使用 continue 语句跳过本轮循环的剩余部分。即程序会使用下一个元素进入下一轮迭代:
for i in range(4):
if i == 2:
continue
else:
print(i)
# 输出结果
0
1
3
使用 while 循环,循环会在条件不满足时停止:
n = 0
while n <= 2:
print(n)
n += 1
# 输出结果
0
1
2
增强赋值:上一个例子中使用了增强赋值(augmented assignment)的写法:n += 1。这和 n = n + 1 是一样的。前面介绍过的其他算术运算符也可以采用同样的写法,比如,可以写成 n -= 1。
3.4.4 列表、字典和集合推导式 #
假设有如下的货币名称对,你想把美元在后面的元素挑出来。你可能会写下面这样一个 for 循环:
currency_pairs = ["USDJPY", "USDGBP", "USDCHF",
"USDCAD", "AUDUSD", "NZDUSD"]
usd_quote = []
for pair in currency_pairs:
if pair[3:] == "USD":
usd_quote.append(pair[:3])
usd_quote、
# 输出结果
['AUD', 'NZD']
这种情况用列表推导式(list comprehension)会更简单。列表推导式是一种更简洁的列表创建方法。
[pair[:3] for pair in currency_pairs if pair[3:] == "USD"]
# 输出结果
['AUD', 'NZD']
字典也有字典推导式:
In [105]: exchange_rates = {"EURUSD": 1.1152,
"GBPUSD": 1.2454,
"AUDUSD": 0.6161}
{k: v * 100 for (k, v) in exchange_rates.items()}
Out[105]: {'EURUSD': 111.52, 'GBPUSD': 124.54, 'AUDUSD': 61.61}
集合也有集合推导式:
In [106]: {s + "USD" for s in ["EUR", "GBP", "EUR", "NZD", "NZD"]}
Out[106]: {'EURUSD', 'GBPUSD', 'NZDUSD'}
3.5 组织代码 #
如何让代码形成可维护的结构:首先会介绍函数的核心知识,然后如何将代码分成不同的 Python 模块。
3.5.1 函数 #
即使只是用 Python 来写一些简单的脚本,你仍然会经常编写函数。函数是所有编程语言中最重要的构造,它们可以让你在程序的任何地方重用同样的代码。
1. 定义函数 #
在 Python 中,需要使用 def 关键字来自定义函数,def 代表函数定义。函数定义的第一行以冒号结束,函数的主体需要缩进。
def function_name(required_argument, optional_argument=default_value, ...):
return value1, value2, ...
必需参数:必需参数(required argument)没有默认值。参数之间用逗号隔开。
可选参数:为参数提供默认值之后,它就成了可选参数(optional argument)。如果没有有意义的默认值,则通常用 None 作为可选参数的默认值。
返回值:return 语句定义了函数的返回值。如果省略了返回值,那么函数就会自动返回 None。Python 允许你返回以逗号隔开的多个返回值,这很方便。
来定义一个函数练习一下,这个函数可以将华氏度或者开氏度转换为摄氏度:
In [107]: def convert_to_celsius(degrees, source="fahrenheit"):
if source.lower() == "fahrenheit":
return (degrees-32) * (5/9)
elif source.lower() == "kelvin":
return degrees - 273.15
else:
return f"Don't know how to convert from {source}"
字符串的 lower 方法可以将给定字符串转换为小写,这样就可以在保持比较字符串的代码照常工作的前提下,接受任何大小写形式的 source 字符串了。完成 convert_to_celsius 的定义后,来看看如何调用它。
2. 调用函数 #
调用一个函数,可以在函数名后加上一对圆括号,并在其中给出参数。
value1, value2, ... = function_name(positional_arg, arg_name=value, ...)
位置参数:如果将一个值作为位置参数(positional argument,即上面的 positional_arg)传递,那么这个值会被传递给对应位置上的参数。
关键字参数:以 arg_name=value 这种形式传递的参数,就是关键字参数(keyword argument)。关键字参数的好处是可以以任意顺序传递参数,并且对于读者来说更加直观易懂。如果函数被定义成 f(a, b),则可以像这样调用:f(b=1, a=2)。
下面来尝试一下 convert_to_celsius 函数,看看它是如何工作的:
In [108]: convert_to_celsius(100, "fahrenheit") # 位置参数
Out[108]: 37.77777777777778
In [109]: convert_to_celsius(50) # 使用默认值(fahrenheit)
Out[109]: 10.0
In [110]: convert_to_celsius(source="kelvin", degrees=0) # 关键字参数
Out[110]: -273.15
3.5.2 模块和 import 语句 #
为大型项目编写代码时,在一定的时候会需要将代码分成不同的文件,从而保持一种可维护的结构。
Python 文件的扩展名为 .py,通常我们会把主要的文件称作脚本(script)。如果你想让你的主脚本获得来自其他文件的概念,则需要先导入(import)那个功能。在这种情况下,Python 源文件被称为模块(module)。
模块只会被导入一次:如果再一次运行 import temperature 单元格,你会注意到 print 函数不会输出任何内容。这是因为 Python 模块在每个会话中只会被导入一次。如果你要导入的模块发生了更改,则需要重启 Python 解释器才能让更改体现出来。在 Jupyter 笔记本中,需要点击“内核 > 重启”。

在使用 import x from y 这样的语法时,你只导入了指定的对象。这些对象被直接导入主脚本的命名空间(namespace)中,也就是说,如果不看这些 import 语句,你就说不清被导入的对象是在你的 Python 脚本(或者 Jupyter 笔记本)中还是在另一个模块中定义的。
不要让你的脚本和既存的包重名:一个常见的错误根源是给你的 Python 文件取一个和既存的包同样的名字。如果你要创建一个测试 pandas 功能的文件,那么不要将其命名为 pandas.py,因为这会造成冲突。
3.5.3 datetime 类 #
要在 Python 中处理日期和时间,可以导入标准库中的 datetime 模块。这个模块包含了一个也叫 datetime 的类,可用于创建 datetime 对象。由于这个类和它所在的模块同名,可能会造成混淆,因此在本书中我会遵循这样的导入规则:import datetime as dt。这样可以更容易区分模块(dt)和类(datetime)。
到目前为止,我们大部分时候是用字面量(literal)来创建列表和字典之类的对象。字面量指的是一种会被 Python 识别为特定类型对象的语法。对于列表来说就是像 [1, 2, 3] 这种写法。然而,大部分的对象需要调用对应的类来创建——这个过程被称为实例化(instantiation),因此对象也被称作类实例(class instance)。和调用函数一样,调用类也需要在类名后跟上一对圆括号,并在圆括号中提供参数。要实例化 datetime 对象,需要像下面这样调用对应的类:
import datetime as dt
dt.datetime(year, month, day, hour, minute, second, microsecond, timezone)
In [118]: # 将datetime模块导入为dt
import datetime as dt
In [119]: # 调用timestamp以创建datetime对象
timestamp = dt.datetime(2020, 1, 31, 14, 30)
timestamp
Out[119]: datetime.datetime(2020, 1, 31, 14, 30)
In [120]: # datetime对象提供了多种属性,比如,想要知道它是几号
timestamp.day
Out[120]: 31
In [121]: # 两个datetime对象求差会返回一个timedelta对象
timestamp - dt.datetime(2020, 1, 14, 12, 0)
Out[121]: datetime.timedelta(days=17, seconds=9000)
In [122]: # 也可以对timedelta进行同样的操作
timestamp + dt.timedelta(days=1, hours=4, minutes=11)
Out[122]: datetime.datetime(2020, 2, 1, 18, 41)
要将 datetime 对象格式化(format)成字符串,可以使用 strftime 方法;要解析(parse)字符串并将其转换为 datetime 对象,可以使用 strptime 函数:
In [123]: # 以特定方式格式化datetime对象
# 也可以使用f字符串: f"{timestamp:%d/%m/%Y %H:%M}"
timestamp.strftime("%d/%m/%Y %H:%M")
Out[123]: '31/01/2020 14:30'
In [124]: # 将字符串解析为datetime对象
dt.datetime.strptime("12.1.2020", "%d.%m.%Y")
Out[124]: datetime.datetime(2020, 1, 12, 0, 0)
3.6 PEP 8:Python 风格指南 #
Python 使用所谓的 Python 改进提案(Python Enhancement Proposals,PEP)来讨论新语言特性的引入。Python 代码的风格指南就是其中之一。这些提案一般用数字来表示,代码风格指南就被称作 PEP 8。PEP 8 是一系列提供给 Python 社区的风格建议。如果使用相同代码的所有人都遵循相同的代码风格,那么写出的代码可读性就会更高。在开源的世界中,会有很多互不相识的程序员开发同一个项目,此时遵循相同的代码风格会显得尤为重要。
"""这个脚本展示了一些PEP 8的规则 ➊
"""
import datetime as dt ➋
TEMPERATURE_SCALES = ("fahrenheit", "kelvin",
"celsius") ➌
➍
class TemperatureConverter: ➎
pass # 暂时不做任何事 ➏
def convert_to_celsius(degrees, source="fahrenheit"): ➐
"""这个函数将华氏度或开氏度转化为摄氏度 ➑
"""
if source.lower() == "fahrenheit": ➒
return (degrees-32) * (5/9) ➓
elif source.lower() == "kelvin":
return degrees - 273.15
else:
return f"Don't know how to convert from {source}"
celsius = convert_to_celsius(44, source="fahrenheit") 11
non_celsius_scales = TEMPERATURE_SCALES[:-1] 12
print("Current time: " + dt.datetime.now().isoformat())
print(f"The temperature in Celsius is: {celsius}")
➊ 在文件顶部用文档字符串(docstring)解释这个脚本或者模块做了些什么。文档字符串是一种特殊的字符串,它用 3 个引号引用。除了作为代码的文档,它还可以用来编写跨越多行的字符串。如果你的字符串中有很多双引号或单引号,那么也可以用文档字符串来避免转义。
➋ 所有的导入语句都应该放在文件顶部,一行一个导入。从标准库导入的内容放在前面,然后是第三方包,最后是自己编写的模块。
➌ 用大写字母和下划线表示常量。每行的长度不超过 79 个字符。尽可能地利用圆括号、方括号或花括号隐式跨行。
➍ 类、函数和其他代码之间用两个空行隔开。
➎ 尽管很多类像 datetime 一样使用小写字母命名,但是你自己编写的类也应该使用首字母大写的名称(CapitalizedWords)。有关类的更多内容请参见附录 C。
➏ 行内注释应该和代码间隔至少两个空格。代码块应该用 4 个空格缩进。
➐ 在能够提高可读性的情况下,函数和参数应该使用小写字母和下划线命名。不要在参数名和默认值之间使用空格。
➑ 函数的文档字符串应当列出函数参数并解释其意义。
➒ 冒号前后不要使用空格。
➓ 可以在算术运算符前后使用空格。如果同时使用了优先级不同的运算符,则应当考虑在优先级最低的运算符前后添加空格。在本例中,由于乘号的优先级最低,因此它的前后被添加了空格。
11:变量名称使用小写字母。在可以提升可读性的前提下使用下划线。为变量赋值时,在等号前后添加空格。不过在调用函数时,不要在关键字参数前后使用空格。
12:在进行索引和切片时,不要在方括号前后使用空格。
3.6.1 PEP 8 和 VS Code #
在使用 VS Code 时,确保代码严格遵循 PEP 8 的最简单方法是使用代码检查器(linter)。代码检查器会检查源代码中的语法和风格错误。vscode 怎么检查代码 • Worktile 社区

3.6.2 类型提示 #
Python 3.5 引入了一个叫作类型提示(type hint)的特性。类型提示也被称为类型标注(type annotation),它允许你声明变量的数据类型。类型提示并不是强制性的,它也不会影响 Python 解释器执行代码。其主要目的是让 VS Code 之类的文本编辑器可以在代码执行前捕获更多错误,不过它也可以增强编辑器的自动补全功能。
mypy 是用于有类型标注的 Python 代码的最受欢迎的类型检查器,是 VS Code 提供的一种代码检查器。要理解类型标注如何工作,先来看下面这段没有类型提示的代码:
x = 1
def hello(name):
return f"Hello {name}!"
现在加上类型提示:
x: int = 1
def hello(name: str) -> str:
return f"Hello {name}!"
一般来说,类型提示在较大的项目中才会更有用。
附录 A Conda 环境 #
A.1 创建新的 Conda 环境 #
在 Anaconda Prompt 中执行下列命令以创建一个名为 xl38 的新环境,该环境使用了 Python 3.8:
(base)> conda create --name xl38 python=3.8
安装完成之后,像下面这样激活新的环境:
(base)> conda activate xl38
(xl38)>
环境名称已从 base 变更为 xl38。现在你可以使用 Conda 或者 pip 在新环境中安装各种包,且不会影响任何其他的环境。(提醒一句:只有在 Conda 中找不到想要的包时才使用 pip。)
首先,再次确认你处于 xl38 环境中,即 Anaconda Prompt 显示的是 (xl38),然后像下面这样安装 Conda 包(注意,这里需要更换为国内镜像源更快):
(xl38)> conda install lxml=4.6.1 matplotlib=3.3.2 notebook=6.1.4 openpyxl=3.0.5 pandas=1.1.3 pillow=8.0.1 plotly=4.14.1 flake8=3.8.4 python-dateutil=2.8.1 requests=2.24.0 sqlalchemy=1.3.20 xlrd=1.2.0 xlsxwriter=1.3.7 xlutils=2.0.0 xlwings=0.20.8 xlwt=1.3.0
确认安装计划之后,最后再来使用 pip 安装剩下的两个包。
(xl38)> pip install pyxlsb==1.0.7 pytrends==4.7.3
这里安装时出现问题,更换镜像源不行的话,需要关闭梯子的系统代理,参考如下:
如果不想使用 base 环境而想使用 xl38 环境来运行本书中的所有示例代码,那么每次启动 Anaconda Prompt 时一定要执行如下命令来激活 xl38 环境:
(base)> conda activate xl38
也就是说,每当本书代码中的 Anaconda Prompt 显示为 (base)> 时,你看到的应该是 (xl38)>。
要停用环境并回到 base 环境,可以输入如下命令:
(xl38)> conda deactivate
想彻底删除环境,可以运行以下命令:
(base)> conda env remove --name xl38
除了按照上面的步骤手动创建 xl38 环境,也可以利用本书配套代码库的 conda 文件夹中的
xl38.yml 环境文件。执行下面的命令就可以完成所有工作:
(base)> cd C:\Users\username\python-for-excel\conda
(base)> conda env create -f xl38.yml
(base)> conda activate xl38
(xl38)>
A.2 禁用自动激活 #
如果不希望在每次启动 Anaconda Prompt 时自动激活 base 环境,你可以禁用它:这样你就需要在命令提示符(Windows 系统)或终端(macOS 系统)中手动输入 conda activate base 才能使用 Python。
在 Windows 中,你需要使用一般的命令提示符而不是 Anaconda Prompt。下面的步骤可以在普通的命令提示符中启用 conda 命令。一定要将第一行中的路径替换成你的计算机上的 Anaconda 安装目录:
> cd C:\Users\username\Anaconda3\condabin
> conda init cmd.exe
现在你的普通命令提示符已经配置好 Conda,接下来就可以像下面这样激活 base 环境了。
> conda activate base
(base)>
附录 B 高级 VS Code 功能 #
B.1 调试器 #
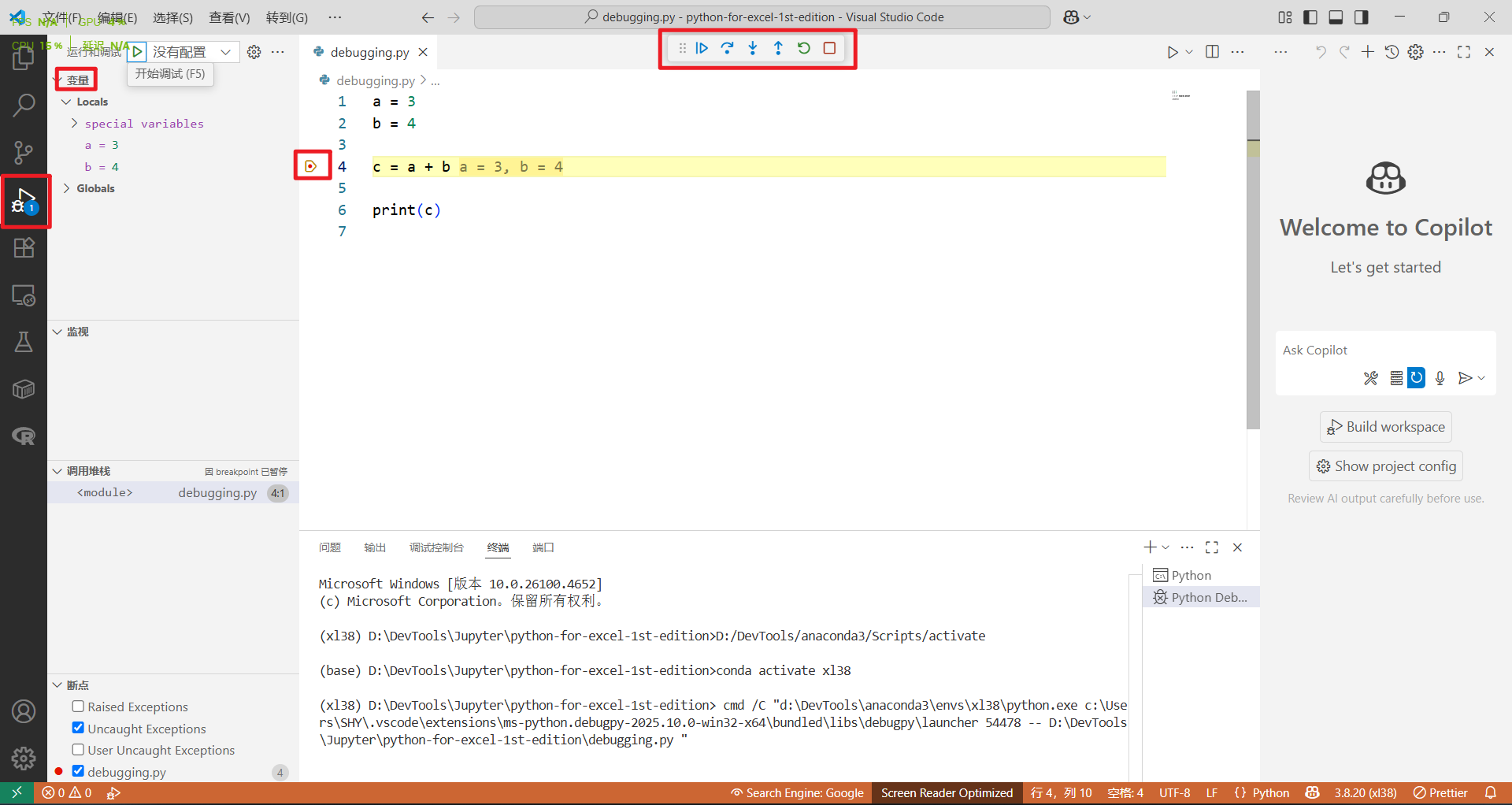
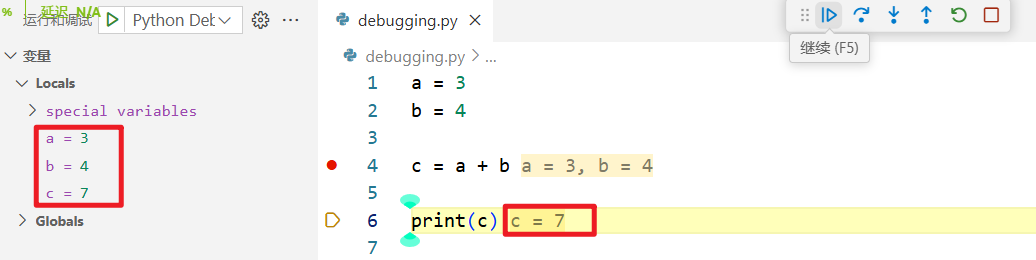
首先在 VS Code 中打开配套代码库的 debugging.py 文件。然后点击第 4 行左边的空白处,你会看到一个红点,这就是断点,代码会在此处暂停执行。接下来按下 F5 键开始调试:命令面板会显示调试配置选项。选择“Python 文件”以调试活动文件,代码会执行到断点处停止。此时这一行代码会高亮显示,代码的执行过程也会暂停。在调试时,状态栏会变成橙色。
如果变量部分没有自动显示在左边,那么一定要点击运行菜单来查看变量的值。另外,也可以将鼠标指针悬停在源代码中的变量上,你会在提示信息中看到它的值。在顶部,你会看到调试工具栏,上面从左到右有这样几个按钮:继续、单步跳过、单步调试、单步跳出、重启和停止。把鼠标指针悬停在这些按钮上时,你还会看到对应的键盘快捷键。
按钮的功能:
1、继续:继续按钮可以让程序继续运行,直到碰到下一个断点或者程序的终点。如果碰到了程序的终点,则调试过程也会停止。
2、单步跳过:调试器会前进一行。单步跳过意味着调试器在视觉上不会进入不属于当前作用域的那部分代码。例如,它不会进入你在各行中调用的函数,但是这些函数还是会被调用。
3、单步调试:如果你调用了函数、类,或其他结构,那么单步调试会使调试器进入这个函数或类。如果这个函数或类在不同的文件中,则调试器会为你打开这个文件。
4、单步跳出:如果你使用单步调试进入了一个函数,则单步跳出会使调试器返回上一层代码,最终你会回到一开始调用单步调试的那一层代码。
5、重启:停止当前的调试进程并重新启动一个新的调试进程。
6、停止:停止当前的调试进程。
B.2 VS Code 中的 Jupyter 笔记本 #
除了在 Web 浏览器中运行 Jupyter 笔记本,也可以直接在 VS Code 中运行 Jupyter 笔记本。除了笔记本的基本功能之外,VS Code 还提供了一个便利的变量浏览器,以及在不丢失单元格功能的前提下将笔记本转换为标准 Python 文件的选项。这样一来调试器的使用就可以更加方便,在不同笔记本之间复制粘贴单元格也会更加便捷。
B.2.1 运行 Jupyter 笔记本 #
点击活动栏中的资源管理器图标,打开配套代码库中的 ch05.ipynb。接下来,需要在弹出窗口中点击信任以使我们的笔记本成为受信任的笔记本。为了让笔记本的布局和 VS Code 的其他部分更协调,VS Code 中的笔记本看起来和浏览器中的布局会有点儿不一样。不过使用体验依然是一样的,连同快捷键也是如此。我们首先按下快捷键 Shift+Enter 来运行前 3 个单元格。如果 Jupyter 笔记本服务器没有启动,那么此时服务器会随之启动(你会在笔记本的右上方看到服务器的状态)。然后,点击笔记本顶部菜单中的计算器按钮:如图 B-2 所示,此时变量浏览器会显示出来,你可以在其中看到现有的所有变量的值。也就是说,你只会在这里看到来自已运行的单元格的变量。
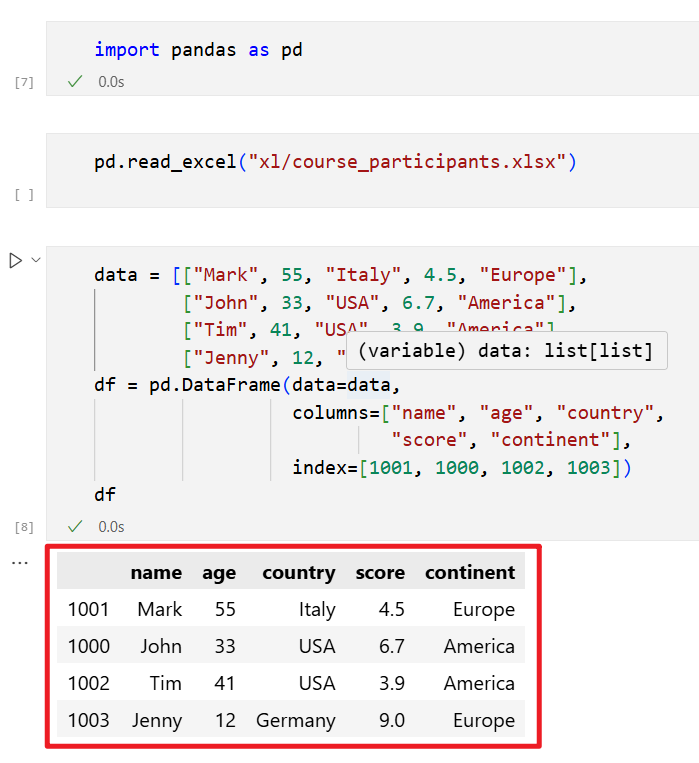
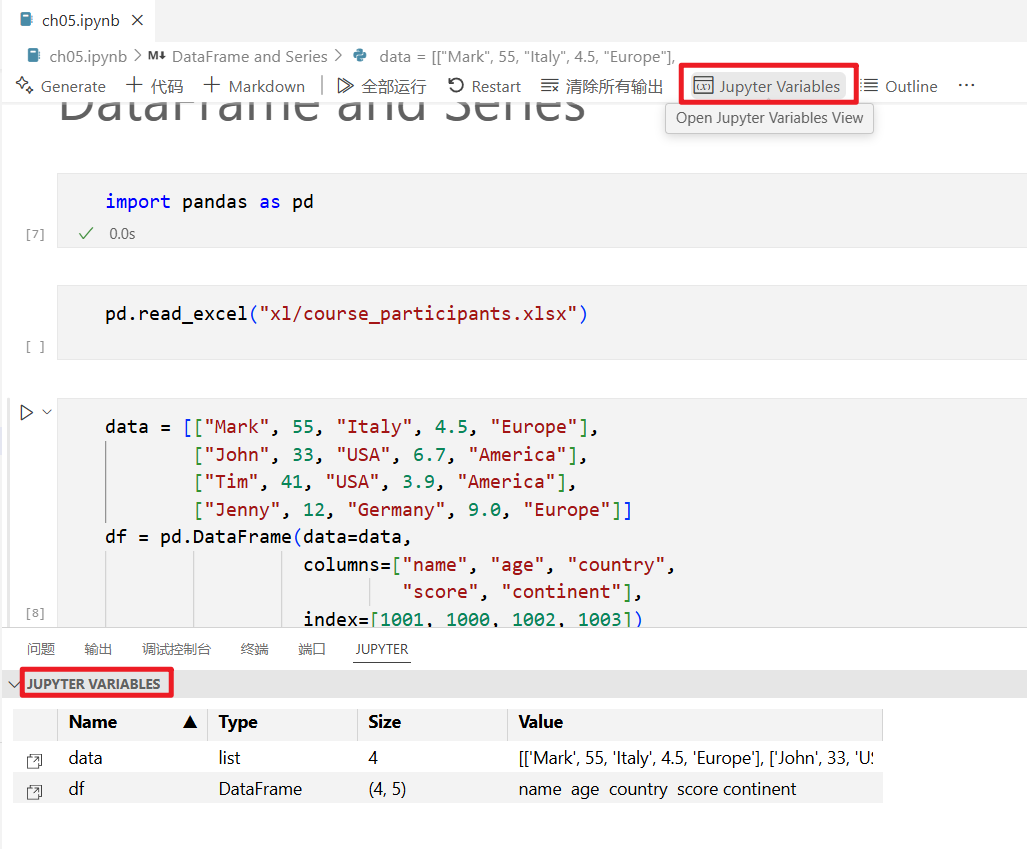
VS Code 中保存 Jupyter 笔记本:要在 VS Code 中保存笔记本,需要使用笔记本顶部的保存按钮,或是在 Windows 中按下快捷键 Ctrl+S。
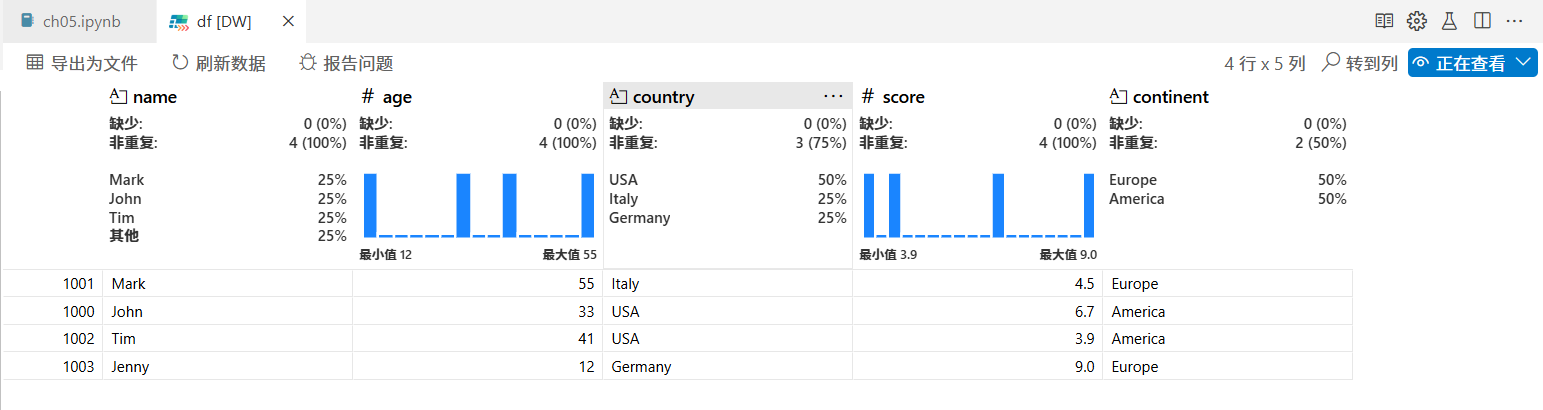
如果使用了像嵌套列表、NumPy 数组、DataFrame 一类的数据结构,那么可以双击变量来打开数据查看器,你会看到熟悉的表格式视图。下图展示了双击变量 df 后显示的数据查看器。

B.2.2 带有代码单元格的 Python 脚本 #
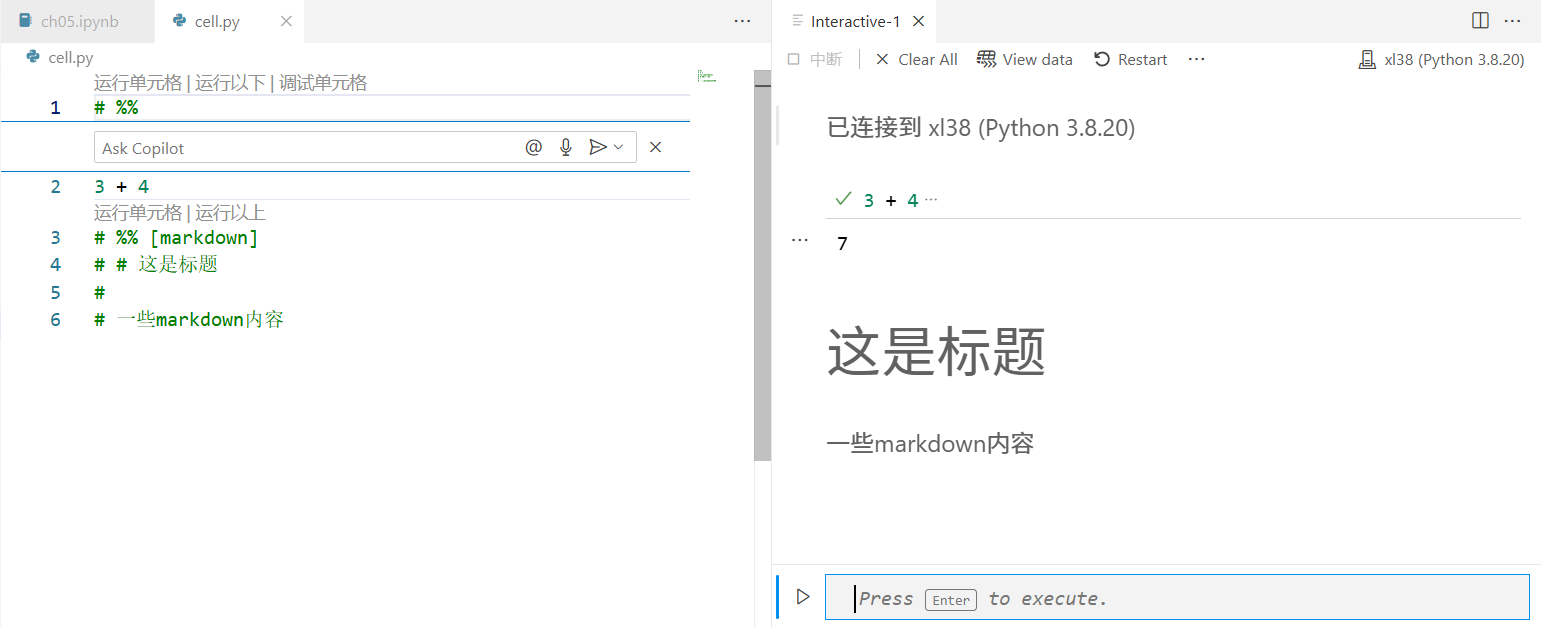
为了在标准 Python 文件中使用 Jupyter 笔记本单元格,VS Code 使用了一种特殊的组件来表示单元格:# %%。要转换现有的 Jupyter 笔记本,可以打开该笔记本并点击笔记本顶部的 export 按钮。这样就可以在命令面板中选择“Python 文件”。不过,我们不会转换现有的文件,而是会新建一个叫作 cell.py 的文件,其中有如下内容:
# %%
3 + 4
# %% [markdown]
# # 这是标题
#
# 一些markdown内容
Markdown 单元格需要以 # %% [markdown] 开头,整个单元格必须被标记为注释。如果你想将这样的文件作为笔记本运行,那么可以将鼠标指针悬停在第一个单元格上,点击显示的“运行本单元格及下方单元格”链接。Python 交互式窗口会在右侧打开,如图所示。
要将文件导出为 ipynb 格式,需要点击 Python 交互式窗口顶部的 save 图标。Python 交互式窗口还在底部提供了一个单元格,你可以在这里交互地执行代码。和 Jupyter 笔记本不同,使用常规的 Python 文件可以利用 VS Code 调试器,并使版本控制更加方便,因为输出单元格会被忽略(在版本发生变化时,输出单元格总是会产生大量烦人的信息)。
