第二部分 pandas 入门 #
第四章 NumPy 基础 #
NumPy 是 Python 科学计算的关键包,为数组运算和线性代数运算提供了支持。因为 pandas 是在 NumPy 之上建立起来的,所以本章会先介绍 NumPy 的基础知识。在解释了什么是 NumPy 数组之后,我们会学习向量化和广播这两个重要概念。利用向量化和广播,我们可以写出简洁的数学运算代码,并且它们在 pandas 中也有广泛运用。之后,介绍为什么 NumPy 会提供叫作“全局函数”的特殊函数。最后,通过解释 NumPy 视图和副本之间的区别,学习如何存取 NumPy 数组的值。
4.1 NumPy 入门 #
介绍一维和二维的 NumPy 数组,以及向量化、广播和通用函数的背景知识。
4.1.1 NumPy 数组 #
对嵌套列表进行数组运算,可以使用循环来完成。要为嵌套列表中的每一个元素都加上 1,可以使用下面的嵌套列表推导式:
In [1]: matrix = [[1, 2, 3],
[4, 5, 6],
[7, 8, 9]]
In [2]: [[i + 1 for i in row] for row in matrix]
Out[2]: [[2, 3, 4], [5, 6, 7], [8, 9, 10]]
但是这样的代码可读性很低。更关键的是,在面对更大的数组时,遍历整个数组会非常慢。如果你的用例和数组大小合适的话,那么使用 NumPy 数组进行运算会比 Python 列表快上几百倍。为了达到如此高的性能,NumPy 利用了用 C 和 Fortran(它们都是编译型语言,比 Python 要快得多)编写的代码。NumPy 数组是保存同构数据(homogenous data)的 N 维数组。“同构”意味着数组中的所有数据都必须是相同类型。最常见的情况就是处理一维和二维的浮点数数组。
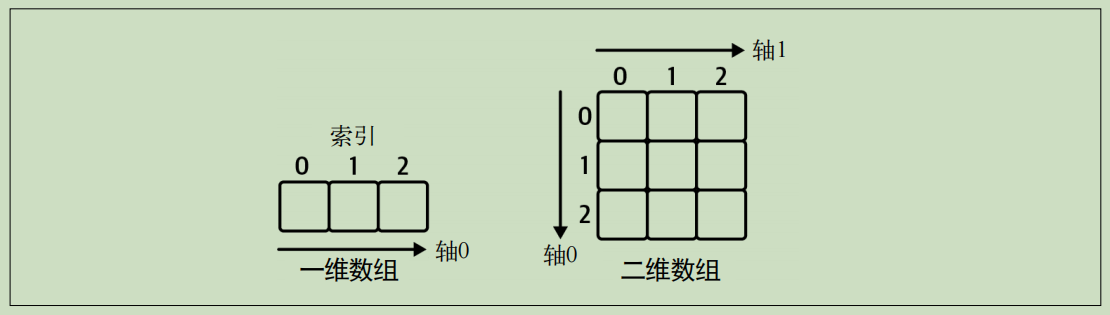
下面来创建一个一维数组和一个二维数组:
In [3]: # 首先导入NumPy
import numpy as np
In [4]: # 使用列表构造一个一维数组
array1 = np.array([10, 100, 1000.])
In [5]: # 使用嵌套列表构造一个二维数组
array2 = np.array([[1., 2., 3.],
[4., 5., 6.]])
数组维度:要注意一维数组和二维数组之间的区别。一维数组只有一个轴,因此不区分行数组和列数组。
即使 array1 除了最后一个元素(浮点数)之外全是整数,但由于 NumPy 对同构的要求,这个数组的数据类型依然是 float64,这个类型足以容纳所有的元素。要想了解一个数组的数据类型,可以访问它的 dtype 属性:
In [6]: array1.dtype
Out[6]: dtype('float64')
如果需要显式地将 NumPy 数据类型转换成 Python 的基本数据类型,只需使用对应的构造器即可:
In [7]: float(array1[0])
Out[7]: 10.0
4.1.2 向量化和广播 #
如果你对一个标量和 NumPy 数组求和,那么 NumPy 会执行按元素的操作。也就是说,你不用亲自遍历每一个元素。NumPy 社区称之为向量化(vectorization)。向量化可以让代码更简洁,更接近于数学记法。
In [8]: array2 + 1
Out[8]: array([[2., 3., 4.],
[5., 6., 7.]])
标量:标量(scalar)指的是某种 Python 基本数据类型,比如浮点型和字符串。这是为了将其和列表及字典一类的多元素数据结构,以及一维和二维的 NumPy 数组区分开来。
在处理两个数组时也是同样的道理,NumPy 会执行按元素的运算:
In [9]: array2 * array2
Out[9]: array([[ 1., 4., 9.],
[16., 25., 36.]])
如果你在算术运算中使用了两个形状不同的数组,那么 NumPy 在可能的情况下会自动将较小的数组扩展成较大的数组的形状。这就是广播(broadcasting):
In [10]: array2 * array1
Out[10]: array([[ 10., 200., 3000.],
[ 40., 500., 6000.]])
要求矩阵的点积,需要使用 @ 运算符:
In [11]: array2 @ array2.T # array2.T是array2.transpose()的缩写形式
Out[11]: array([[14., 32.],
[32., 77.]])
拓展:矩阵的点积,也称为内积或标量积,在数学中是一种重要的矩阵运算。它涉及两个矩阵中对应元素的乘积和随后的求和,结果是一个单一的标量值。对于两个向量 a 和 b,它们的点积是这样计算的:a ⋅ b = a1b1 + a2b2 + … + anbn,其中 a1, a2, …, an 和 b1, b2, …, bn 是向量 a 和 b 的对应元素。如果将这个概念扩展到矩阵,矩阵的点积就是两个矩阵对应元素乘积的总和。
4.1.3 通用函数 #
通用函数(universal function,简称 ufunc)会对 NumPy 数组中的每个元素执行操作。如果在 NumPy 数组中使用 Python 标准库 math 模块中的开平方函数,那么你会得到一个错误:
In [12]: import math
In [13]: math.sqrt(array2) # 这里会发生错误
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-13-5c37e8f41094> in <module>
----> 1 math.sqrt(array2) # 这里会发生错误
TypeError: only size-1 arrays can be converted to Python scalars
可以写一个嵌套循环来计算每个元素的平方根,然后再把结果构造成一个 NumPy 数组:
In [14]: np.array([[math.sqrt(i) for i in row] for row in array2])
Out[14]: array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
NumPy 有这样一个 ufunc,直接用它,除了更容易输入和阅读,在处理大型数组时 ufunc 会快得多:
In [15]: np.sqrt(array2)
Out[15]: array([[1. , 1.41421356, 1.73205081],
[2. , 2.23606798, 2.44948974]])
NumPy 的一些 ufunc 也可以用作数组的方法。以 sum 为例,如果你想求出每一列的总和,那么可以像下面这样做:
In [16]: array2.sum(axis=0) # 返回一维数组
Out[16]: array([5., 7., 9.])
参数 axis=0 表示以行为轴,参数 axis=1 表示以列为轴。省略 axis 参数会将整个数组加起来:
In [17]: array2.sum()
Out[17]: 21.0
4.2 创建和操作数组 #
4.2.1 存取元素 #
在处理本章开头例子中的 matrix 这类嵌套列表时,可以使用链式索引(chained indexing):matrix[0] [0]会得到第一行的第一个元素。不过在 NumPy 数组中,你要在一对方括号中同时提供两个维度的索引和切片参数:
numpy_array[row_selection, column_selection]
对于一维数组,上述代码简化成了 numpy_array[selection]。在选取单个元素时,你会得到一个标量,否则得到的就是一维或二维的数组。对二维数组的行或列进行切片,得到的是一个一维数组,而不是二维列向量或行向量。

In [18]: array1[2] # 返回标量
Out[18]: 1000.0
In [19]: array2[0, 0] # 返回标量
Out[19]: 1.0
In [20]: array2[:, 1:] # 返回二维数组
Out[20]: array([[2., 3.],
[5., 6.]])
In [21]: array2[:, 1] # 返回一维数组
Out[21]: array([2., 5.])
In [22]: array2[1, :2] # 返回一维数组
Out[22]: array([4., 5.])
4.2.2 方便的数组构造器 #
通过 arange 和 reshape,可以快速生成指定维度的数组:
In [23]: np.arange(2 * 5).reshape(2, 5) # 2行,5列
Out[23]: array([[0, 1, 2, 3, 4],
[5, 6, 7, 8, 9]])
以蒙特卡罗模拟为例,一个常见需求是生成服从正态分布的伪随机数数组。NumPy 可以轻松做到:
In [24]: np.random.randn(2, 3) # 2行,3列
Out[24]: array([[-0.30047275, -1.19614685, -0.13652283],
[ 1.05769357, 0.03347978, -1.2153504 ]])
还有一些方便的构造器值得去发掘,比如 np.ones 和 np.zeros,它们分别可以创建全是 1 和 0 的数组。np.eye 可以创建单位矩阵。
4.2.3 视图和副本 #
在对 NumPy 数组切片时,其返回值是视图(view)。这就意味着你是在操作原数组的一个子集,而没有发生数据的复制。因而设置视图的值也会改变原数组中的值:
In [25]: array2
Out[25]: array([[1., 2., 3.],
[4., 5., 6.]])
In [26]: subset = array2[:, :2]
subset
Out[26]: array([[1., 2.],
[4., 5.]])
In [27]: subset[0, 0] = 1000
In [28]: subset
Out[28]: array([[1000., 2.],
[ 4., 5.]])
In [29]: array2
Out[29]: array([[1000., 2., 3.],
[ 4., 5., 6.]])
如果不想要这样的结果,那么可以把 In [26] 的代码改成下面这样:
subset = array2[:, :2].copy()
对副本进行操作不会影响原数组。
第五章 使用 pandas 进行数据分析 #
pandas,即 Python 数据分析库(Python data analysis library),pandas 最主要的超能力就是向量化和数据对齐。首先会介绍如何清理和准备数据,然后你会了解到如何通过聚合、描述性统计量和可视化让大型数据集更易于理解。本章在结尾部分会介绍如何用 pandas 导入和导出数据。不过首先,先来了解一下 pandas 最主要的数据结构:DataFrame 和 Series。
5.1 DataFrame 和 Series #
DataFrame(数据帧)和 Series(序列)是 pandas 的核心数据结构。本节会对 DataFrame 的主要组件——索引、列和数据逐一介绍。DataFrame 和二维的 NumPy 数组类似,但是它的行和列有对应的标签,并且每一列都可以存储不同类型的数据。从 DataFrame 中提取一行或一列时,你会得到一个一维的 Series。类似地,Series 相当于带标签的一维 NumPy 数组。
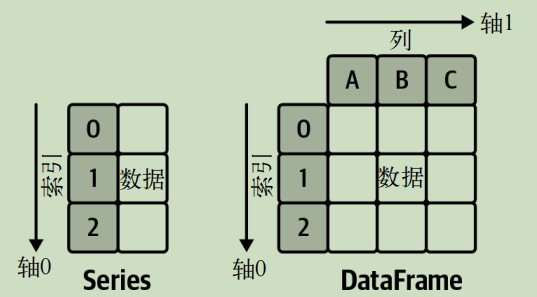
从工作表到 DataFrame 的过渡非常简单,下图的 Excel 表格中展示了网课学员的基本信息及其分数。你可以在配套代码库的 xl 文件夹中找到对应的 course_participants.xlsx 文件。
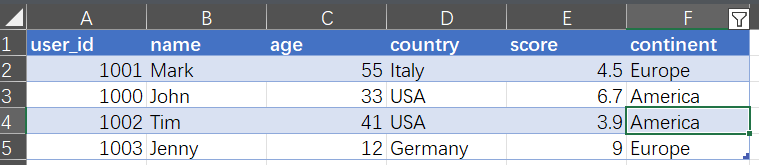
为了能在 Python 中使用这个 Excel 表格,首先要导入 pandas,然后使用 read_excel 函数通过 Excel 文件构造一个 DataFrame。
In [1]: import pandas as pd
In [2]: pd.read_excel("xl/course_participants.xlsx")
Out[2]: user_id name age country score continent
0 1001 Mark 55 Italy 4.5 Europe
1 1000 John 33 USA 6.7 America
2 1002 Tim 41 USA 3.9 America
3 1003 Jenny 12 Germany 9.0 Europe
在 Python 3.9 中使用 read_excel 函数如果你在 Python 3.9 或者更高版本中使用 pd.read_excel 函数,那么一定要确保 pandas 版本在 1.2 以上,否则会在读取 xlsx 文件时发生错误。
参考:https://geek-docs.com/python/python-ask-answer/346_hk_1709853930.html
通过 Python 代码查看 Pandas 版本:
import pandas as pd
print(pd.__version__)
这里的报错处理如下:修改已经弃用的 np.float 为 float。
创建 DataFrame 的方法之一是利用嵌套列表来提供数据,除了数据本身,还需要提供 columns 参数和 index 参数:
In [3]: data=[["Mark", 55, "Italy", 4.5, "Europe"],
["John", 33, "USA", 6.7, "America"],
["Tim", 41, "USA", 3.9, "America"],
["Jenny", 12, "Germany", 9.0, "Europe"]]
df = pd.DataFrame(data=data,
columns=["name", "age", "country",
"score", "continent"],
index=[1001, 1000, 1002, 1003])
df
Out[3]: name age country score continent
1001 Mark 55 Italy 4.5 Europe
1000 John 33 USA 6.7 America
1002 Tim 41 USA 3.9 America
1003 Jenny 12 Germany 9.0 Europe
调用 info 方法可以获得 DataFrame 的一些基本信息,其中最重要的是数据点数量和每一列的数据类型:
In [4]: df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4 entries, 1001 to 1003
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 4 non-null object
1 age 4 non-null int64
2 country 4 non-null object
3 score 4 non-null float64
4 continent 4 non-null object
dtypes: float64(1), int64(1), object(3)
memory usage: 192.0+ bytes
如果只对列的数据类型感兴趣,那么可以执行 df.dtypes。如果列含有字符串或者混合了不同数据类型,那么它的数据类型就是 object。
5.1.1 索引 #
DataFrame 的行标签被称为索引(index)。如果你找不到一个有意义的索引,那么在构造 DataFrame 时可以直接省略,pandas 会自动创建一个从 0 开始的整数索引。
获取索引对象:
In [5]: df.index
Out[5]: Int64Index([1001, 1000, 1002, 1003], dtype='int64')
可以的话,应该给索引取一个名字。根据 Excel 表格对应的列名,我们给索引取名为 user_id:
In [6]: df.index.name = "user_id"
df
Out[6]: name age country score continent
user_id
1001 Mark 55 Italy 4.5 Europe
1000 John 33 USA 6.7 America
1002 Tim 41 USA 3.9 America
1003 Jenny 12 Germany 9.0 Europe
和数据库中的主键不同,DataFrame 的索引可以重复,但是这种情况下查询速度可能会变慢。要将索引还原成普通的列,可以使用 reset_index,而 set_index 可以设置一个新的索引。如果在设置新索引时不想丢掉原本的索引,那么一定要先重置索引:
In [7]: # reset_index会将索引还原为普通列,同时用默认索引替换当前索引
# 最终结果就和刚从Excel文件中得到的DataFrame一样
df.reset_index()
Out[7]: user_id name age country score continent
0 1001 Mark 55 Italy 4.5 Europe
1 1000 John 33 USA 6.7 America
2 1002 Tim 41 USA 3.9 America
3 1003 Jenny 12 Germany 9.0 Europe
In [8]: # reset_index会将user_id还原成普通列
# set_index会将"name"列设置为索引
df.reset_index().set_index("name")
Out[8]: user_id age country score continent
name
Mark 1001 55 Italy 4.5 Europe
John 1000 33 USA 6.7 America
Tim 1002 41 USA 3.9 America
Jenny 1003 12 Germany 9.0 Europe
df.reset_index().set_index(“name”) 这种形式的代码被称为链式方法调用(method chaining):reset_index() 会返回一个 DataFrame,你可以直接在这个 DataFrame 上调用另一个方法而无须写出中间值。
DataFrame 的方法返回的是副本:每当以 df.method_name() 的形式调用 DataFrame 的方法时,你都会得到一个应用了该方法的 DataFrame 副本,而原来的 DataFrame 没有任何变化。刚刚调用的 df.reset_index() 就是这样的。如果你想改变原来的 DataFrame,那么可以把返回值赋值给原来的变量:
df = df.reset_index()
用 reindex 方法更换索引:
In [9]: df.reindex([999, 1000, 1001, 1004])
Out[9]: name age country score continent
user_id
999 NaN NaN NaN NaN NaN
1000 John 33.0 USA 6.7 America
1001 Mark 55.0 Italy 4.5 Europe
1004 NaN NaN NaN NaN NaN
reindex 会接管所有能够匹配新索引的行,而无法匹配的索引会引入含有空值(NaN)的行。被忽略的索引所对应的行会被直接丢弃。最后,使用 sort_index 可以按索引进行排序:
In [10]: df.sort_index()
Out[10]: name age country score continent
user_id
1000 John 33 USA 6.7 America
1001 Mark 55 Italy 4.5 Europe
1002 Tim 41 USA 3.9 America
1003 Jenny 12 Germany 9.0 Europe
如果你想按一列或多列进行排序,可以使用 sort_values:
In [11]: df.sort_values(["continent", "age"])
Out[11]: name age country score continent
user_id
1000 John 33 USA 6.7 America
1002 Tim 41 USA 3.9 America
1003 Jenny 12 Germany 9.0 Europe
1001 Mark 55 Italy 4.5 Europe
如果只想按某一列进行排序,那么也可以用列名字符串作为参数:
df.sort_values("continent")
5.1.2 列 #
执行如下代码可以获得 DataFrame 列的信息:
In [12]: df.columns
Out[12]: Index(['name', 'age', 'country', 'score', 'continent'], dtype='object')
如果在构造 DataFrame 时没有提供列名,那么 pandas 会用从 0 开始的数字为列编号。不过在处理列的时候这并不是一个好主意,列代表着各种变量,要取个名字并非难事。为列命名与命名索引类似:
In [13]: df.columns.name = "properties"
df
Out[13]: properties name age country score continent
user_id
1001 Mark 55 Italy 4.5 Europe
1000 John 33 USA 6.7 America
1002 Tim 41 USA 3.9 America
1003 Jenny 12 Germany 9.0 Europe
如果不喜欢某些列的列名,可以进行重命名:
In [14]: df.rename(columns={"name": "First Name", "age": "Age"})
Out[14]: properties First Name Age country score continent
user_id
1001 Mark 55 Italy 4.5 Europe
1000 John 33 USA 6.7 America
1002 Tim 41 USA 3.9 America
1003 Jenny 12 Germany 9.0 Europe
如果想删除某些列,可以使用如下语法(这个例子还体现了如何在删除列的同时删除索引):
In [15]: df.drop(columns=["name", "country"], index=[1000, 1003])
Out[15]: properties age score continent
user_id
1001 55 4.5 Europe
1002 41 3.9 America
DataFrame 的列和索引都是由 Index 对象表示的,通过转置(transpose)DataFrame 可以将行和列对调:
In [16]: df.T # df.transpose()的简写
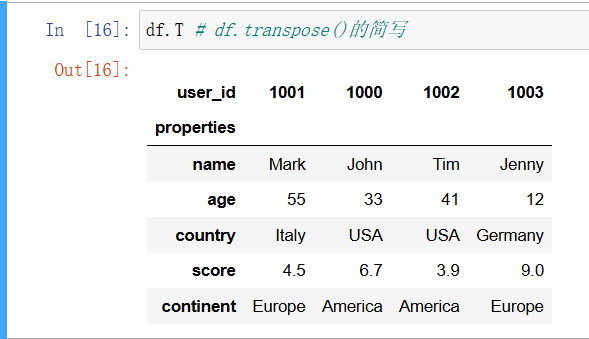
要记住的是,我们的 DataFrame df 仍然原封不动,因为并没有将方法返回的 DataFrame 赋值给原来的 df 变量。如果需要更改 DataFrame 列的顺序,那么也可以使用用在索引上的 reindex 方法,不过直接给出所需要的列顺序通常会更直观:
In [17]: df.loc[:, ["continent", "country", "name", "age", "score"]]
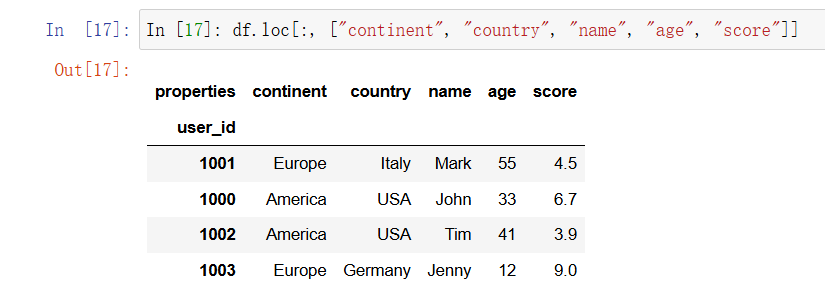
5.2 数据操作 #
在使用数据之前,需要对其进行清理,使其更易于理解。如何从 DataFrame 中选取数据,如何修改数据,以及如何处理缺失和重复的数据。然后再对 DataFrame 进行一些运算,看看如何处理文本数据。
5.2.1 选取数据 #
1. 使用标签选取数据 #
访问 DataFrame 数据的最常见方式是用它的标签来引用数据。使用 loc 属性(代表 location,位置)指定你想获取的行和列:
df.loc[row_selection, column_selection]
loc 支持切片语法,因此可以用冒号来选取所有的行或者列。你既可以提供保存标签的列表作为参数,也可以只提供单个行或者列的名称作为参数。
从 df 这个 DataFrame 中选取部分数据的方法:


标签切片是闭区间:和 Python 内置的切片语法以及 pandas 的其他地方不同,在使用标签切片时,标签的区间包含区间首尾的两个标签。
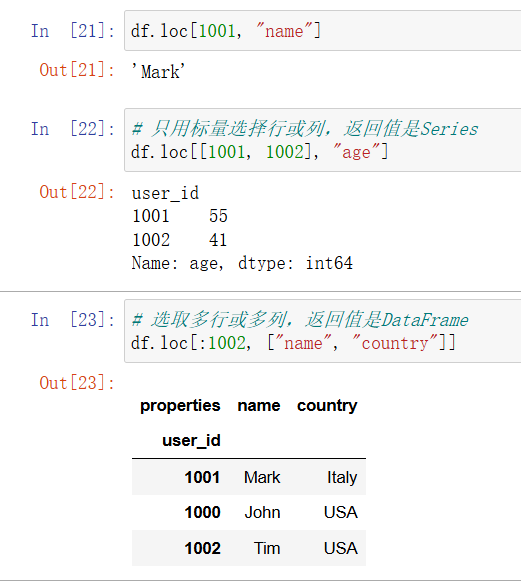
In [18]: # 行和列都使用标量来选择,返回值也是标量
df.loc[1001, "name"]
In [19]: # 只用标量选择行或列,返回值是Series
df.loc[[1001, 1002], "age"]
In [20]: # 选取多行或多列,返回值是DataFrame
df.loc[:1002, ["name", "country"]]
DataFrame(无论是一列还是多列)与 Series 之间是有区别的,理解这一点至关重要。即使只包含一列,DataFrame 也是二维的数据结构,而 Series 永远是一维的。DataFrame 和 Series 都有索引,但只有 DataFrame 有列标题。当你选取一列生成 Series 时,列标题就变成了 Series 的名称。
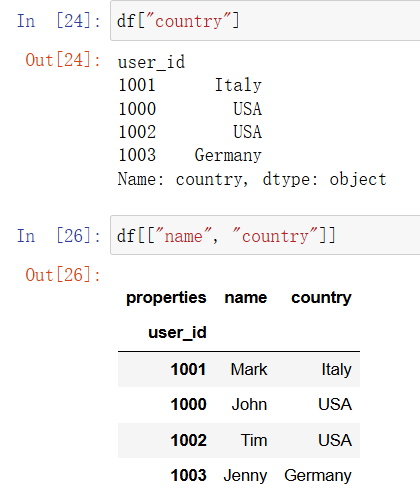
列选择的捷径: 列的选取是十分常见的操作,pandas 为其提供了更简单的写法。除了这样写:
df.loc[:, column_selection]
也可以这样写:
df[column_selection]
例 如,df[“country”] 会从我们的示例 DataFrame 中返回一个 Series, 而 df[[“name”, “country”]] 会返回一个包含两列的 DataFrame。
2. 通过位置选取数据 #
通过位置选取 DataFrame 的子集类似于本章开头在 NumPy 数组上进行的操作。不过对于 DataFrame 来说,需要使用 iloc 属性,它的意思是整数位置(integer location):
df.iloc[row_selection, column_selection]
在使用切片时,iloc 使用的是标准的半开半闭区间。
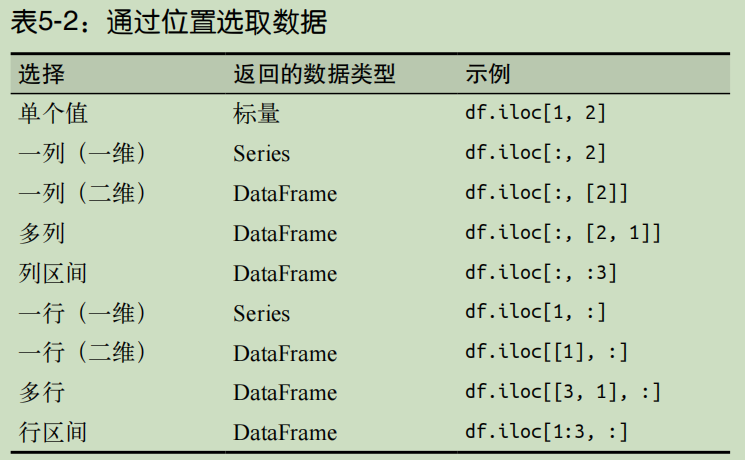
In [21]: df.iloc[0, 0] # 返回标量
In [22]: df.iloc[[0, 2], 1] # 返回Series
In [23]: df.iloc[:3, [0, 2]] # 返回DataFrame
3. 使用布尔索引选取数据 #
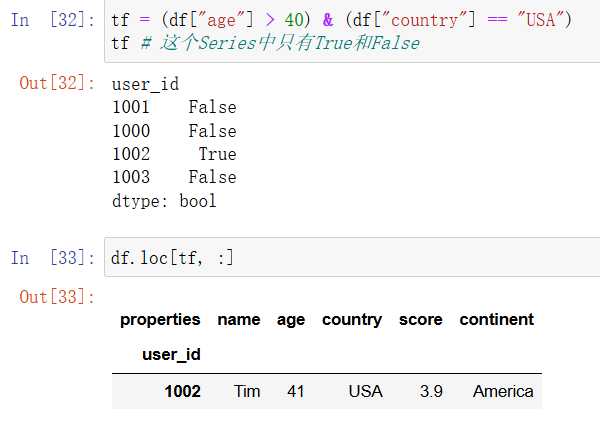
布尔索引(boolean indexing)是借助只包含 True 或 False 的 Series 或 DataFrame 来选取一个 DataFrame 的子集。布尔 Series 可以用来选取 DataFrame 的特定列和行,布尔 DataFrame 则用来选取整个 DataFrame 中的某些值。布尔索引最常见的用例是用来筛选 DataFrame 的行。
In [24]: tf = (df["age"] > 40) & (df["country"] == "USA")
tf # 这个Series中只有True和False
In [25]: df.loc[tf, :]
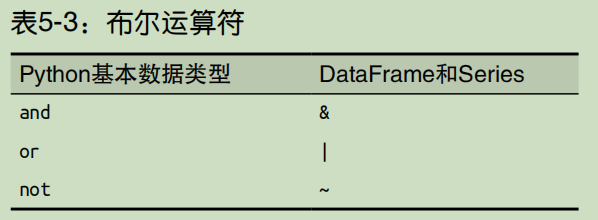
第一,由于技术上的限制,你无法在 DataFrame 中使用第 3 章讲到的 Python 布尔运算符。需要使用表 5-3 中的这些符号。
第二,如果你的筛选条件不止一条,那么一定要在每条布尔表达式之间加上圆括号,这样可以防止运算符优先级造成的问题:例如,& 运算符的优先级比 == 高。
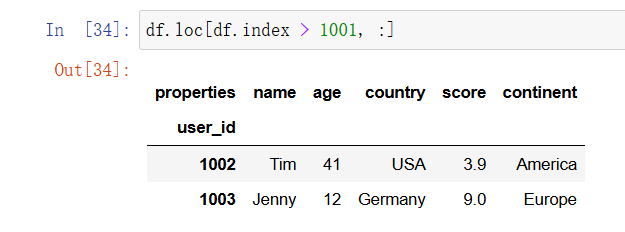
对索引进行筛选,那么可以用 df.index 来引用索引对象:
In [26]: df.loc[df.index > 1001, :]
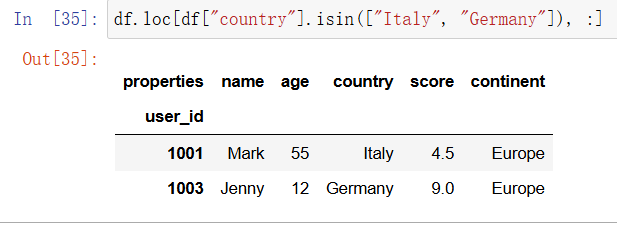
Python 的基本数据结构(如列表)可以使用 in 运算符判断是否包含某些对象,如果要在 Series 中进行类似的操作,就需要使用 isin 方法。可以像下面这样筛选出所有来自意大利和德国的学员:
In [27]: df.loc[df["country"].isin(["Italy", "Germany"]), :]
DataFrame 还提供了一种特殊的语法,可以在不使用 loc 的情况下传递一整个布尔 DataFrame 作为参数:
df[boolean_df]
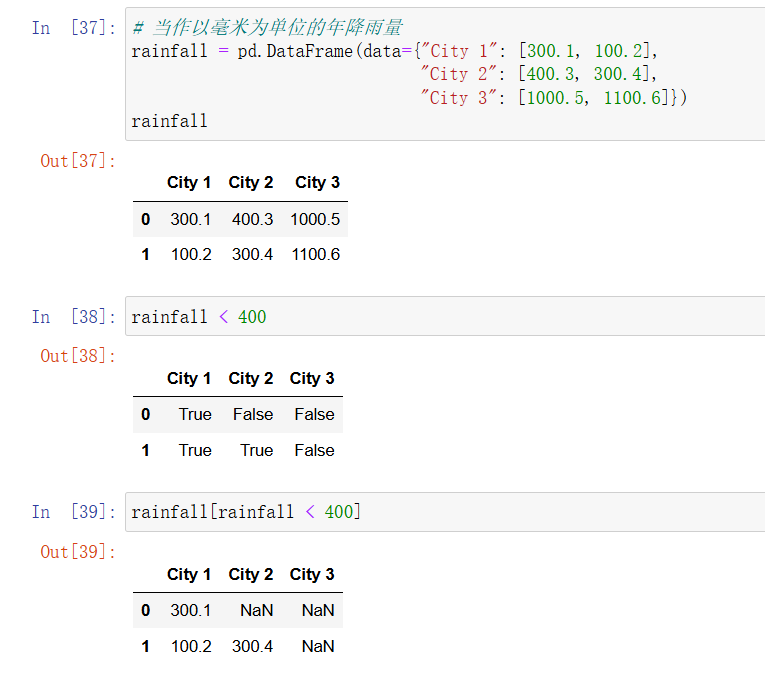
在 DataFrame 只包含数字时这种语法特别有用。当提供这样一个布尔 DataFrame 作为参数时,返回的 DataFrame 会在原 DataFrame 的基础上,把对应着 False 的地方变成 NaN。下面先来创建一个新的示例 DataFrame,命名为 rainfall,它只包含数字:
In [28]: # 当作以毫米为单位的年降雨量
rainfall = pd.DataFrame(data={"City 1": [300.1, 100.2],
"City 2": [400.3, 300.4],
"City 3": [1000.5, 1100.6]})
rainfall
In [29]: rainfall < 400
In [30]: rainfall[rainfall < 400]
要注意在这个例子中,我使用了字典来构造一个新的 DataFrame。如果数据本身就是这种形式的话,这是很方便的。布尔值的这种用法经常被用来排除某些值,比如异常值。
4. 使用 MultiIndex 选取数据 #
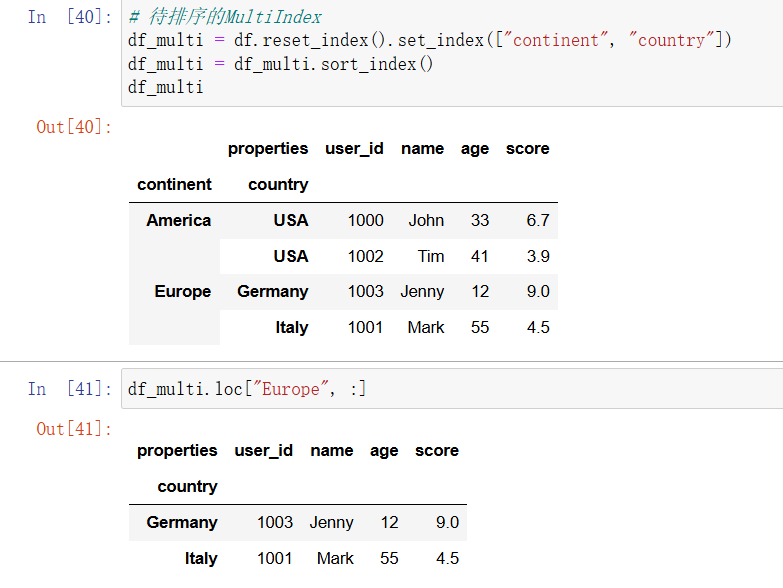
MultiIndex 是一种多级索引。它可以将数据按层次分组,这样你就可以更方便地访问 DataFrame 的子集。如果将 continent 和 country 一起设置为 df 这个 DataFrame 的索引,那么你就可以轻松地通过某个大洲的名称来选取对应的所有行:
In [31]: # 待排序的MultiIndex
df_multi = df.reset_index().set_index(["continent", "country"])
df_multi = df_multi.sort_index()
df_multi
In [32]: df_multi.loc["Europe", :]
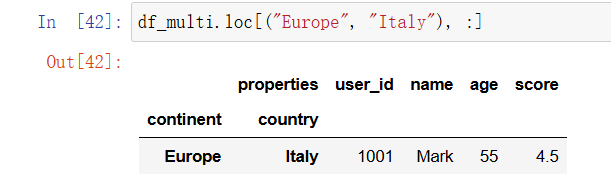
通过多级索引选取数据需要提供一个元组作为参数:
In [33]: df_multi.loc[("Europe", "Italy"), :]
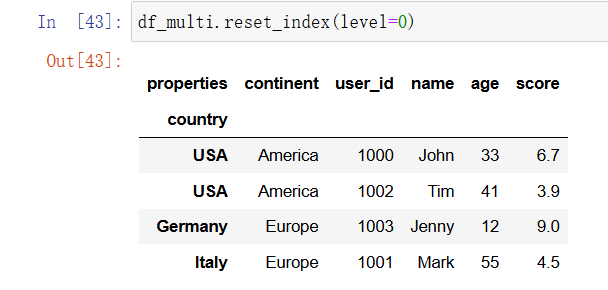
想选择性地重置一部分 MultiIndex,那么可以为 reset_index 提供索引级别参数。索引级别从左至右从 0 开始:
In [34]: df_multi.reset_index(level=0)
5.2.2 设置数据 #
修改 DataFrame 数据的最简单的方法是通过 loc 和 iloc 属性为某些元素赋值。
1. 通过标签或位置设置值 #
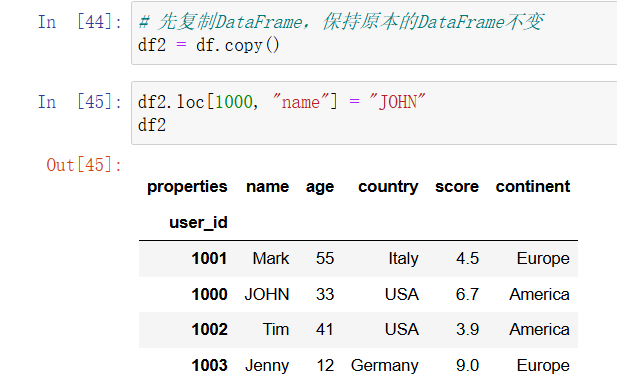
当你以 df.reset_index() 的形式调用 DataFrame 的方法时,方法总是会被应用到一个副本上,而原本的 DataFrame 是原封不动的。然而通过 loc 属性和 iloc 属性赋值时,原本的 DataFrame 是会被修改的。由于不想修改 df 这个 DataFrame,因此在这里我创建了一个名为 df2 的副本。如果你想修改某一个值,那么可以像下面这样做:
In [35]: # 先复制DataFrame,保持原本的DataFrame不变
df2 = df.copy()
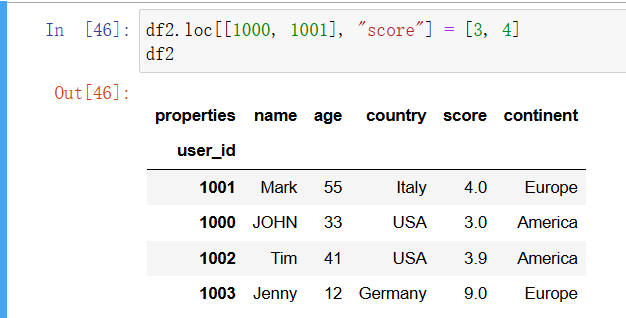
下面是同时修改 ID 为 1000 和 1001 的两名用户分数的一种方法,这里使用了一个列表作为参数:
In [37]: df2.loc[[1000, 1001], "score"] = [3, 4]
df2
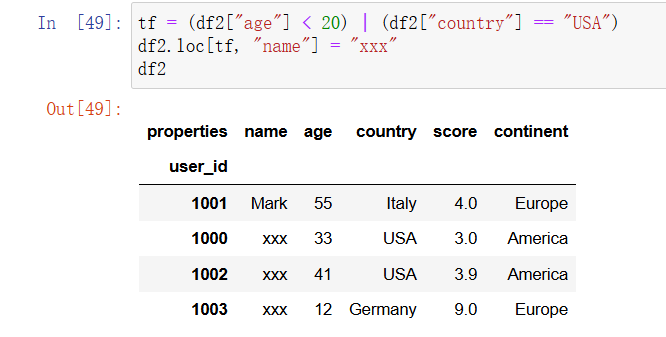
2. 通过布尔索引设置数据 #
用来筛选行的布尔索引也可以用来为 DataFrame 赋值。假设你需要将所有来自美国或年龄在 20 岁以下的学员匿名:
In [38]: tf = (df2["age"] < 20) | (df2["country"] == "USA")
df2.loc[tf, "name"] = "xxx"
df2
有时可能需要将整个数据集中的某个值完全替换,而不是只涉及特定的列。在这种情况下,可以再一次利用这种特殊语法,将一个布尔 DataFrame 作为参数(示例中再一次用到了 rainfall 这个 DataFrame):
In [39]: # 先复制DataFrame,保持原本的DataFrame不变
rainfall2 = rainfall.copy()
rainfall2
In [40]: # 将小于400的值用0替换
rainfall2[rainfall2 < 400] = 0
rainfall2

3. 通过替换值设置数据 #
如果想将整个 DataFrame(或者指定列)中的某个值全部替换成另一个值,那么可以使用 replace 方法:
In [41]: df2.replace("USA", "U.S.")
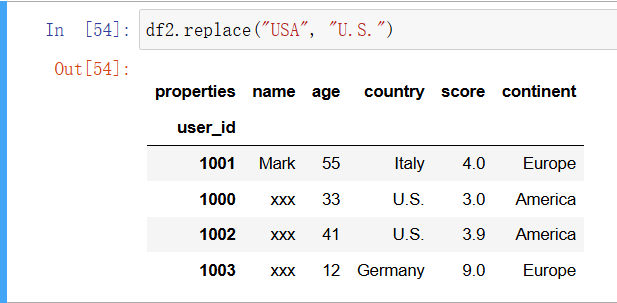
如果只想在 country 列上进行操作,则可以用这种语法:
df2.replace({"country": {"USA": "U.S."}})
4. 通过添加新列设置数据 #
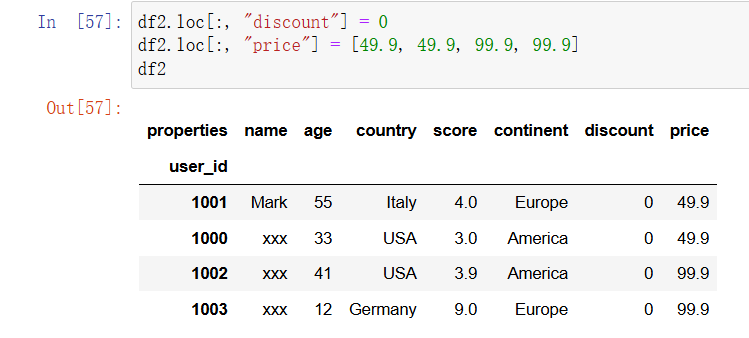
为一个新的列名赋值时会为 DataFrame 添加一个新列。例如,利用一个标量或者列表可以为 DataFrame 添加新列:
In [42]: df2.loc[:, "discount"] = 0
df2.loc[:, "price"] = [49.9, 49.9, 99.9, 99.9]
df2
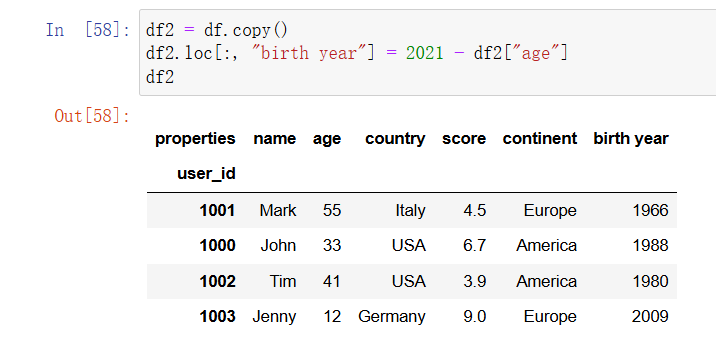
添加新列时经常涉及向量化运算:
In [43]: df2 = df.copy() # 从一个新的副本开始
df2.loc[:, "birth year"] = 2021 - df2["age"]
df2
5.2.3 缺失数据 #
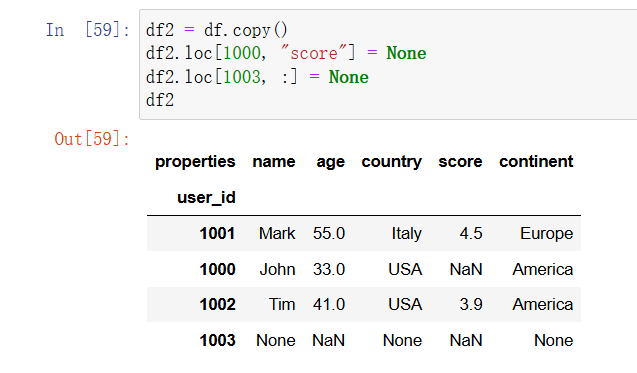
数据的缺失可能会对数据分析的结果造成影响,数据集中有空白是很常见的情况,并且你还不得不对其进行处理。在 Excel 中,你通常必须用空白单元格或者 #N/A 错误进行处理,不过 pandas 使用 NumPy 的 np.nan 代表缺失数据,显示为 NaN。NaN 是浮点数标准中的 Not-a-Number(非数字)。对于时间戳,则是使用 pd.NaT,而文本使用的是 None。可以使用 None 或者 np.nan 来表示缺失的值:
In [44]: df2 = df.copy() # 从一个新的副本开始
df2.loc[1000, "score"] = None
df2.loc[1003, :] = None
df2
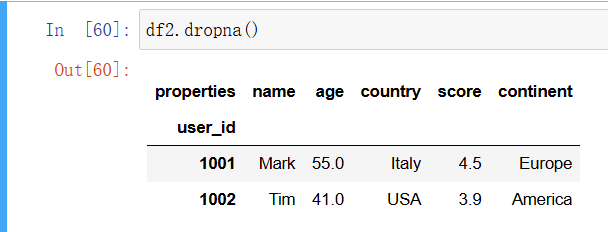
在清理 DataFrame 时,你可能想要移除所有包含缺失数据的行。就这么简单:
In [45]: df2.dropna()
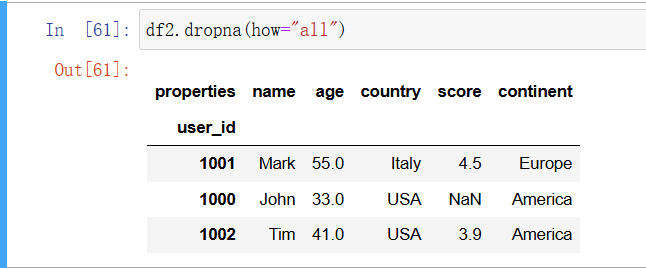
如果只想移除所有值都缺失了的行,那么可以使用 how 参数:
In [46]: df2.dropna(how="all")
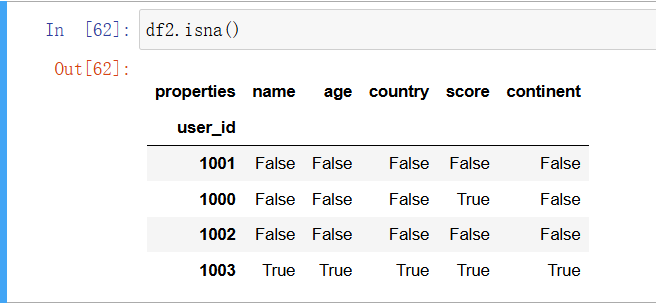
想获得一个反映对应位置上是否是 NaN 的布尔 DataFrame 或 Series,可以使用 isna 方法:
In [47]: df2.isna()
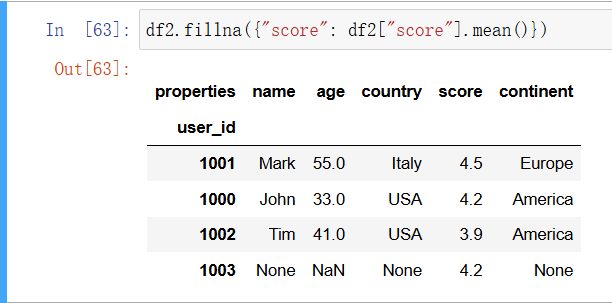
使用 fillna 来填补缺失的值。例如,将数据点数量列中的 NaN 替换为平均分:
In [48]: df2.fillna({"score": df2["score"].mean()})
5.2.4 重复数据 #
和缺失数据一样,重复数据也会对数据分析的可靠性造成负面影响。可以使用 drop_duplicates 方法来清理重复的行。也可以提供列的子集作为参数:
In [49]: df.drop_duplicates(["country", "continent"])
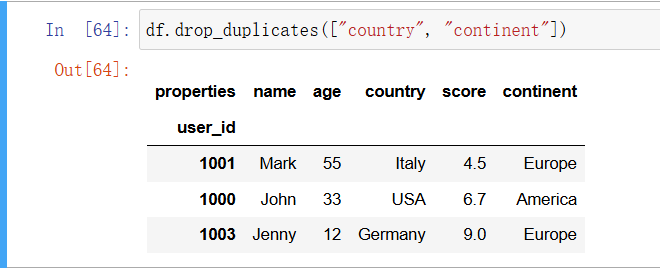
在默认情况下,第一次出现的数据会得以保留。is_unique 用于确认某一列是否包含重复数据,unique 则可以获得去重后的值。(如果想对索引进行此类操作,那么可以将 df[“country”] 换成 df.index。)
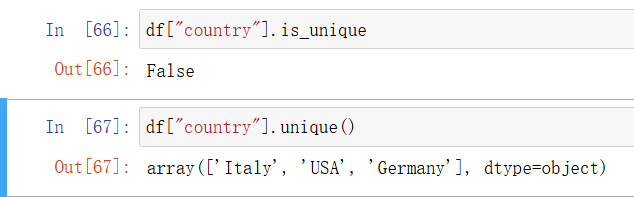
In [50]: df["country"].is_unique
In [51]: df["country"].unique()
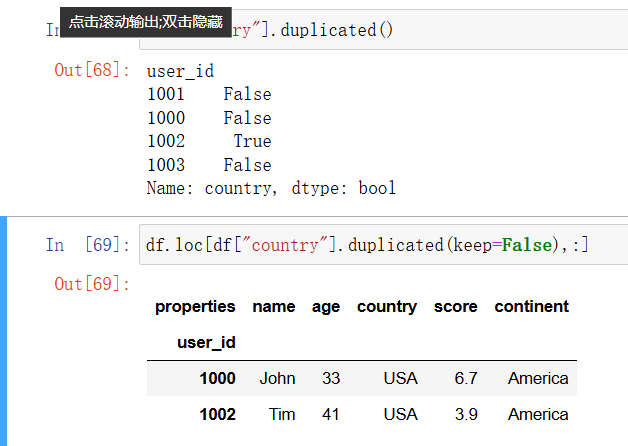
通过 duplicated 方法可以知道哪些行是重复的,它的返回值是一个布尔 Series。keep 参数的默认值是 “first”,意思是会保留第一次出现的数据,只将重复数据标记为 True。将 keep 设置为 False 时,所有的重复数据(包括第一次出现时)都会被标记为 True,这样就可以方便地得到一个包含所有重复行的 DataFrame。在下面的例子中,我们在找 country 列的重复数据,但在实际工作中,通常都是找重复的索引或者整行的重复数据。这个时候就要使用 df.index.duplicated() 或 df.duplicated():
In [52]: # 在默认情况下,只有重复的行会被标记为True,
# 即数据第一次出现时不会被标记为True
df["country"].duplicated()
In [53]: # 要找到所有"country"发生重复的行,
# 可以将参数设置为keep=False
df.loc[df["country"].duplicated(keep=False), :]
5.2.5 算术运算 #
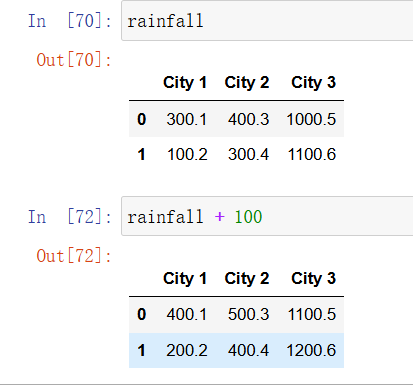
和 NumPy 数组一样,DataFrame 和 Series 也利用了向量化技术。例如,要为 rainfall 这个 DataFrame 中的每一个值加上一个数,只需像下面这样做:
In [54]: rainfall
In [55]: rainfall + 100
不过 pandas 真正的强大之处是它的自动数据对齐(data alignment)机制:当你对多个 DataFrame 使用算术运算符时,pandas 会自动将它们按照列或行索引对齐。下面再创建一个和 rainfall 有相同行列标签的 DataFrame。然后求两者之和:
In [56]: more_rainfall = pd.DataFrame(data=[[100, 200], [300, 400]],
index=[1,2],
columns=["City 1", "City 4"])
more_rainfall
In [57]: rainfall + more_rainfall
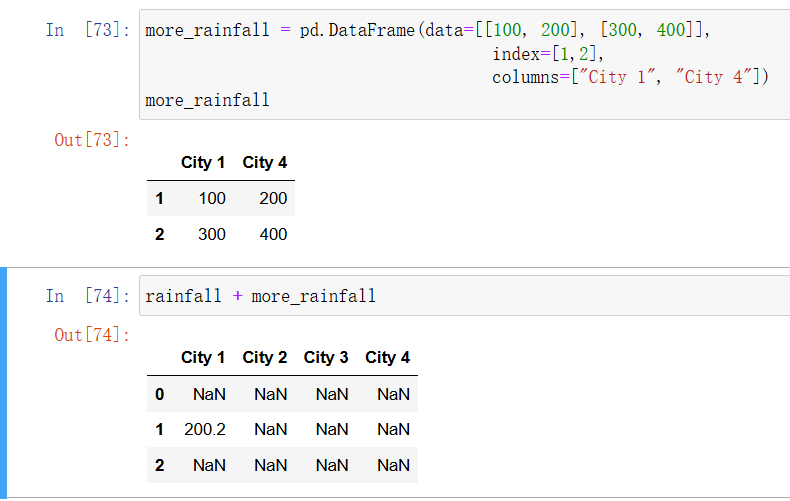
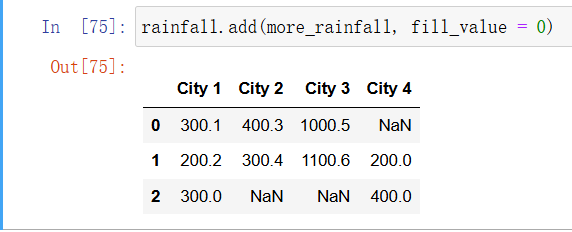
结果 DataFrame 的索引和列是两个 DataFrame 的并集:两个 DataFrame 中都有的字段会被相加,而其他的部分会显示为 NaN。要让 pandas 和 Excel 以同样的方式处理这个问题,可以使用 add 方法,并将 fill_value 参数设置为 0 以代替默认的 NaN:
In [58]: rainfall.add(more_rainfall, fill_value=0)
当算式的操作数是一个 DataFrame 和一个 Series 时,默认情况下 Series 会按索引进行广播:
In [59]: # 用一行数据生成一个Series
rainfall.loc[1, :]
In [60]: rainfall + rainfall.loc[1, :]
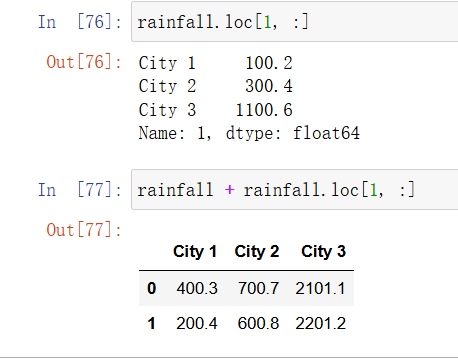
如果要按列加上一个 Series,则需要在调用 add 方法时显式地提供 axis 参数:
In [61]: # 用一列数据生成一个Series
rainfall.loc[:, "City 2"]
In [62]: rainfall.add(rainfall.loc[:, "City 2"], axis=0)
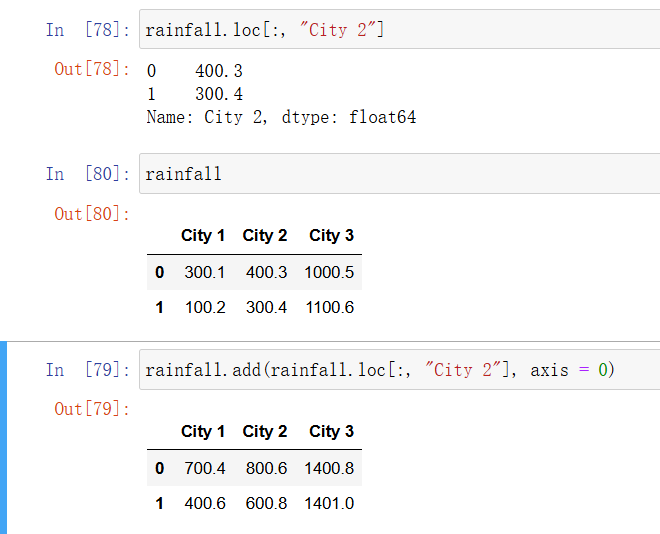
5.2.6 处理文本列 #
含有文本数据的列和含有不同类型数据的列的数据类型是 object。要在含有文本字符串的列上执行相关操作,需要使用 str 属性。str 属性可以访问 Python 的字符串方法。要移除字符串首尾的空白,可以使用 strip 方法;要将首字母大写,可以使用 capitalize 方法。将这些方法组合起来之后,可以将人工输入的乱七八糟的数据清理干净:
In [63]: # 来创建一个新的DataFrame
users = pd.DataFrame(data=[" mArk ", "JOHN ", "Tim", " jenny"],
columns=["name"])
users
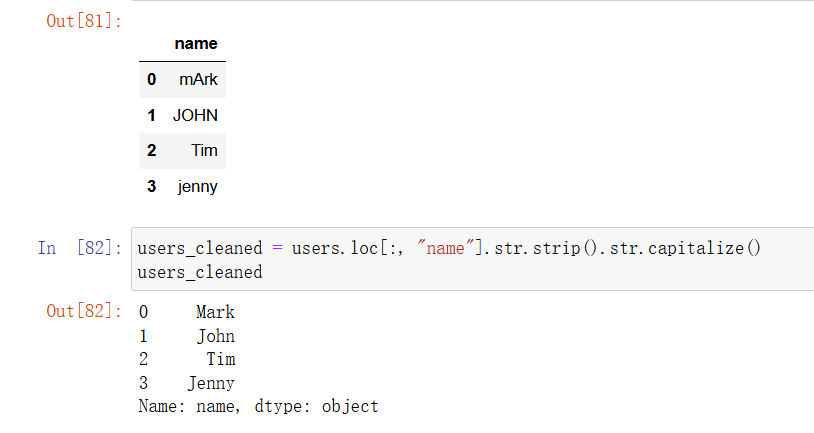
In [64]: users_cleaned = users.loc[:,"name"].str.strip().str.capitalize()
users_cleaned
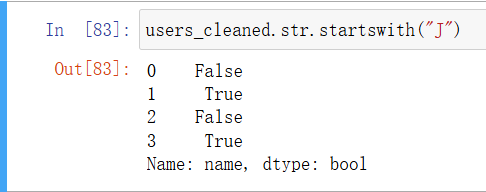
可以像下面这样找到所有以“J”开头的名字:
In [65]: users_cleaned.str.startswith("J")
字符串方法很好用,但是有时候要对 DataFrame 进行的操作可能并没有在对应的内置函数上。在这种情况下,你可以创建自己的函数,再将其应用到 DataFrame 上。
5.2.7 应用函数 #
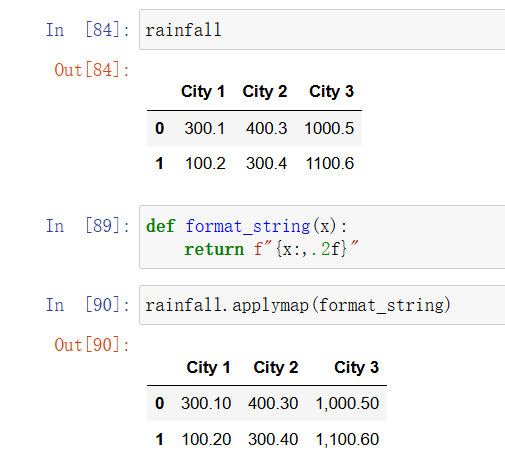
DataFrame 提供了 applymap 方法,它会将一个函数应用到每一个元素上,在 NumPy 没有提供所需的 ufunc 时,这是非常有用的。例如,NumPy 并没有提供字符串格式化的 ufunc,但可以像下面这样为 DataFrame 的每一个元素进行格式化:
In [66]: rainfall
In [67]: def format_string(x):
return f"{x:,.2f}"
In [68]: # 注意,我们并没有调用作为参数的函数,
# 也就是说,这里写的是format_string而非format_string()!
rainfall.applymap(format_string)
这个 f 字符串会将 x 以字符串的形式返回:f"{x}"。要对其进行格式化,需要在变量后面加一个冒号,然后跟上具体的格式化字符串,这里使用的是 ,.2f。这个逗号是千位上的分隔符,而 .2f 的意思是以浮点数格式显示,小数点后保留两位。
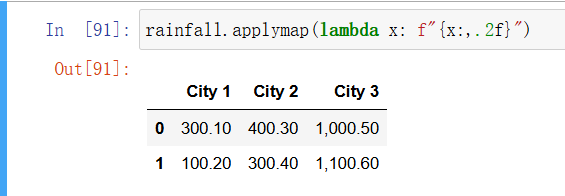
在这样的用例中会经常用到 lambda 表达式(参见“lambda 表达式”)。lambda 表达式可以让你在一行代码中编写一个函数,而不用单独去定义一个函数。通过 lambda 表达式,可以将前面的例子改写成下面这样。
In [69]: rainfall.applymap(lambda x: f"{x:,.2f}")
lambda 表达式:lambda 表达式是一种匿名函数,也就是一种没有名称的函数。假设有这样一个函数:
def function_name(arg1, arg2, ...):
return return_value
可以用 lambda 表达式重写这个函数:
lambda arg1, arg2, ...: return_value
简而言之,把 def 换成 lambda,省去 return 关键字,然后将函数的所有内容写到一行。
5.2.8 视图和副本 #
由于修改视图和修改副本有着本质的区别,因此当 pandas 认为你在无意中修改数据时,它会发出警告:SettingWithCopyWarning。关于如何规避这个相当难以捉摸的警告,下面是一些建议。
• 在原本的 DataFrame 中设置值,而不是在切片生成的 DataFrame 中操作。
• 如果你想在切片后获得一个单独的 DataFrame,则应该显式地调用 copy。
selection = df.loc[:, ["country", "continent"]].copy()
虽然 loc 和 iloc 的情况很复杂,但是记得一点,诸如 df.dropna() 或 df.sort_value(“column_name”) 这样的 DataFrame 方法总是返回副本。
